
Python-1 intermediate-Level Python Tips
by
파이썬의 main문
파이썬의 큰 특징중 한 가지는, C와 달리 main문이 존재하지 않는다는 것이다.
직접 실행한 파일과, import로 불러온 모듈(파일)만이 존재한다.
파이썬의 내장 변수 중 __ name __ 을 이용하면 직접 실행한 파일은 __ name __ 내장 변수를 사용시 __ name __ 값에 __ main __ 이라는 값이 담기고, import해온 모듈은 __ name __ 값에 모듈이름이 담기는 것을 알 수 있다.
따라서
if __name__ __ =="__main__" :
이라는 조건문을 활용한다면 그 아래는 직접 실행시켰을 때에만 실행되기를 원하는 코드를 넣어주어 효율적인 프로그래밍이 가능해진다.
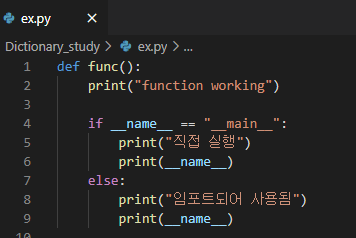
(import할 모듈의 내용)
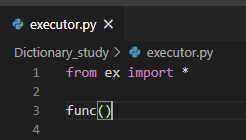
(import한 모습)

(결과 : 직접 실행한 파일의 __ name __ 은 __ main __ 이고 따라서 else문이 실행되었음을 알 수 있다.)
참고로, 파이썬에서 모듈을 import 하면 그 모듈을 찾기 위해 다음과 같은 경로를 순서대로 검색한다.
- 현재 디렉토리
- 환경변수 PYTHONPATH에 지정된 경로
- Python이 설치된 경로 및 그 밑의 라이브러리 경로
assert
assert는 디버깅 보조 도구 이다.
이 문장 앞에 Assertion 구문이 없었다면, 코드가 도는 도중 문제가 발생했을 때, 디버깅 하는것이 생각보다 쉽지 않을 것이다.
assert 에러시 AssertionError가 발생한 위치를 확인하여 쉽게 디버깅 할 수 있다.
if문과 다른 점은, if는 조건이 틀려도 에러를 발생시키지 assert는 에러를 발생시키기에, 체크포인트로 활용할 수 있다는 장점이 있다.
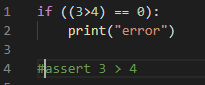

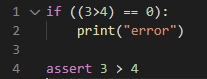

(코드가 멈추고 체크포인트를 확인할 수 있는 모습이다.)
lambda
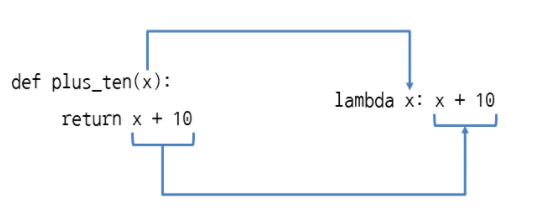
lambda는 쓰고 버리는 일시적인 함수 이다.
즉, 간단한 기능을 일반적인 함수와 같이 정의해두고 쓰는 것이 아니고 필요한 곳에서 즉시 사용하고 버릴 수 있다.
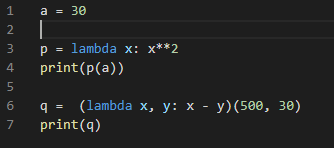

람다 옆에 소괄호를 주어 값을 바로 할당할 수도 있다.
또한 람다 표현식 바깥에 있는 변수 a를 활용할 수 도 있다.
map
파이썬의 내장 함수인 map()는 여러 개의 데이터를 한 번에 다른 형태로 변환하기 위해서 사용된다.
따라서, 여러 개의 데이터를 담고 있는 list에 사용하는것이 용이하다.
map(변환 함수, 리스트) 형태를 띈다.
map의 결과는 map 결과이기에 반드시 list를 사용하여 리스트로 변환해주어야 리스트로 보인다.

(assert 이용하기)

List Comprehension
여기 를 참고하였습니다.
Comprehension은 이해력 이라는 뜻을 의미하는 단어이다.
List Comprehension은 쉽게 말해 ‘리스트를 쉽게, 짧게 한 줄로 만들 수 있는 파이썬의 문법’이다.
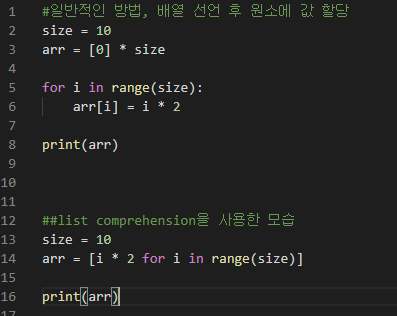
일반적 방법으로는 리스트를 선언 후, 리스트 내 원소에 값을 할당하였는데,
List Comprehension을 이용하면 리스트의 선언과 원소에 값 할당이 한 stage에 동시에 일어난다.
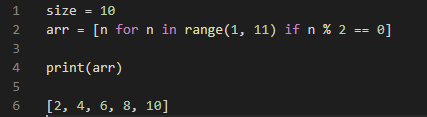
List Comprehension은 다음과 같은 구조를 갖는다.
[ ( 변수를 활용한 값 ) for ( 사용할 변수 이름 ) in ( 순회할 범위 )]

다음은 List comprehension에 조건문을 추가한 모습이다.

fstring
[여기] (https://bluese05.tistory.com/70) 를 참고하였습니다.
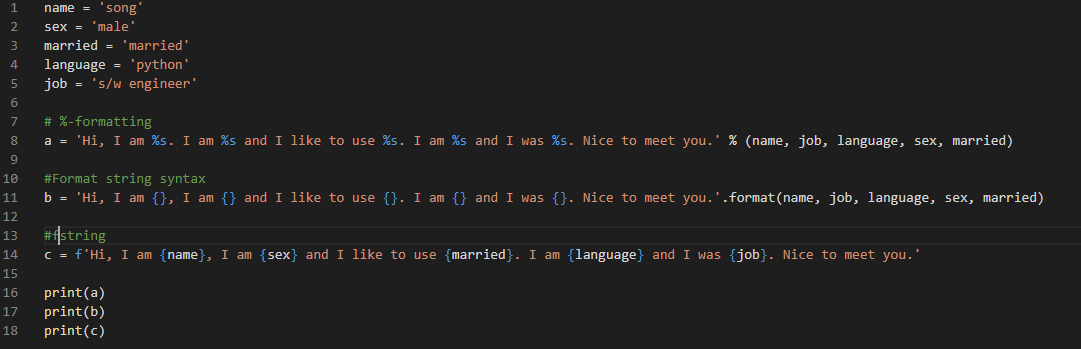
문자열을 다룰 때 %s 등에 값을 대입할 떄 가독성을 매우 향상시켜주는 방법이다.
python 3.6 이상 버전에서 지원된다.
기존 존재하던 %-formatting 방식과 Format string syntax 인 str.format() 방식의 가독성 문제를 보완해준다.
그리고 문자열에 표현하고자 하는 대상 변수의 type에 대해 자유도가 더 높은 모습을 보인다.
기존 %-formatting 은 기본적으로 int, string, double 형만 지원했기에 인자로 tuple형은 못넣어주고 str로 변환하여 주어야 헀는데, fstring에서는 바로 넣어주면 된다.
(튜플 : 리스트와 달리 그 원소 값의 생성, 삭제, 수정이 불가능한 것)

yield
여기를 참고하여 만들었습니다.
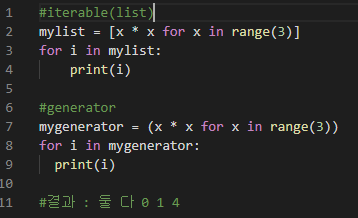
리스트([])와 같이 이터러블한 것들은 우리가 원하는 만큼 접근해서 사용할 수 있기 때문에 모든 값을 메모리에 담고 있어야 하기에 큰 값을 다룰 때에는 별로 좋지 않다.
반면 제너레이터(generators)는 이터레이터(iterators)이다.
제너레이터(())는 모든 값을 메모리에 담고 있지 않고 그때그때 값을 생성(generator)해서 반환하기 때문에 제너레이터를 사용할 때에는 한 번에 한 개의 값만 순환(iterate) 할 수 있다.
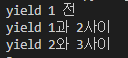
제너레이터는 0을 계산해서 반환한 후 0에 대해서는 아예 잊는다, 그리고 1을 계산하고 한 번에 하나씩 처리해가며 순환을 종료한다.
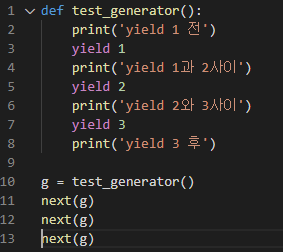
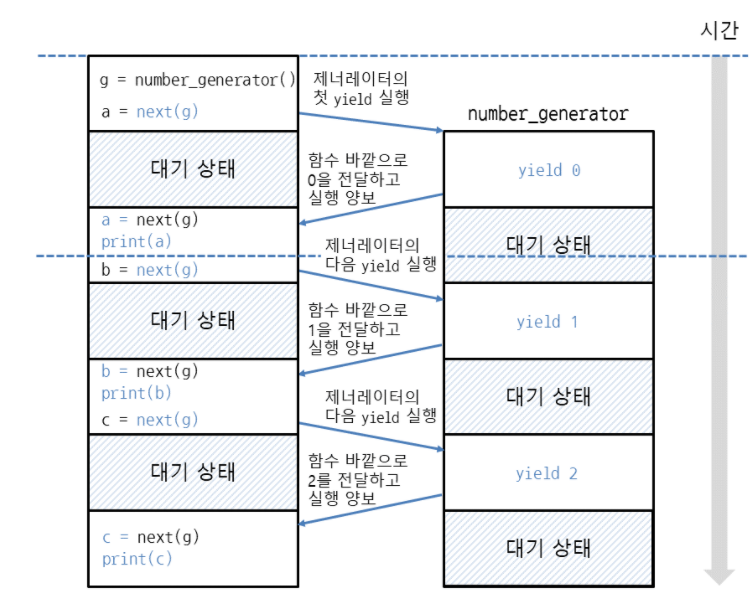
제너레이터는 함수 안에서 yield 키워드를 사용하고, yield의 역할은 return과 같이 함수 밖으로 빠져나가게 하지만, 다시 함수에 접근하면 yield 이후 문 부터 다시 함수가 작동하는 모습을 보인다.
딕셔너리 sorting 하기
파이썬의 딕셔너리는 정렬을 지원하지 않고, 오로지 삽입 순서만을 유지한다.
따라서 딕셔너리를 key나, value 값에 따라 sorting 할 수 있는 팁을 설명한다.
1. 딕셔너리를 lambda함수를 이용하여 key값이나, value값으로 정렬된 튜플들의 list로 감싼다.
(countries.items()은 dict_items()라는 class인데 (dict_items([('Taiwan', 36193), ('Canada', 9984670), 과 같은 모양), 이를 sorted를 통해 list로 감싸준것)
2. 이 list를 다시 dict로 감싸주어 딕셔너리로 만들어준다.
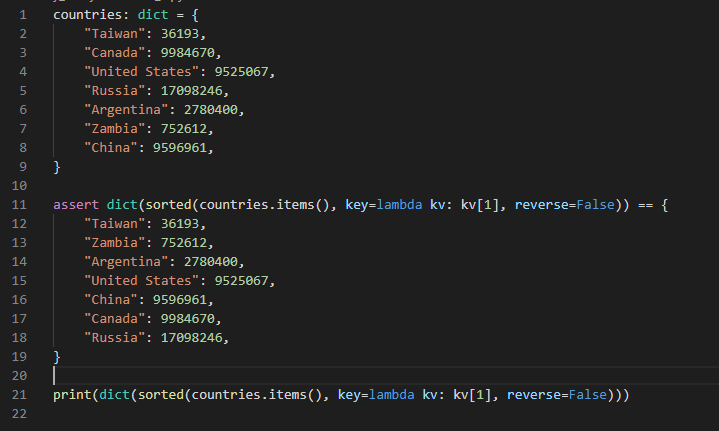

(assert를 사용하여 assertionError가 나면 코드가 멈추도록 구성하였고, value의 정방향 순서로 딕셔너리가 잘 정렬되었음을 확인 할 수 있다.)
(https://medium.com/python-in-plain-english/16-intermediate-level-python-dictionary-tips-tricks-and-shortcuts-1376859e1adc)
에 가면 자세한 정보를 얻을 수 있습니다.
Subscribe via RSS