
Pretraining, Fine tuning and Deconvolution
by
(다음엔 Bottleneck effect, Batch normalization and Convolution 하기) 본 포스트 여기를 바탕으로 작성하였습니다.
Deconvolution
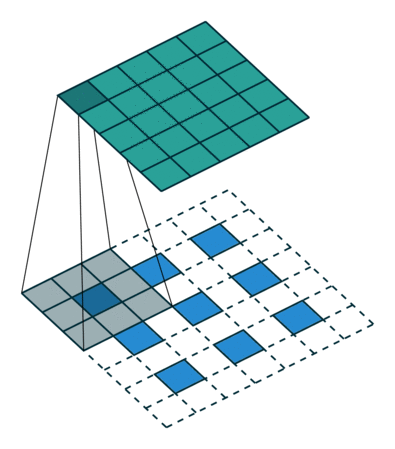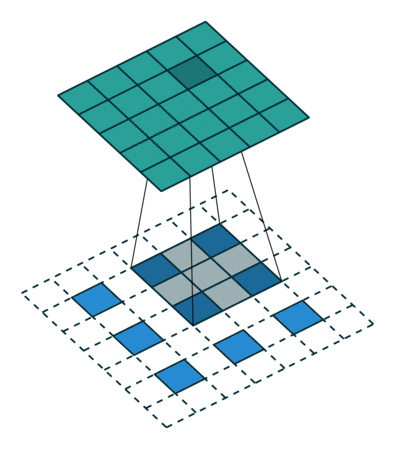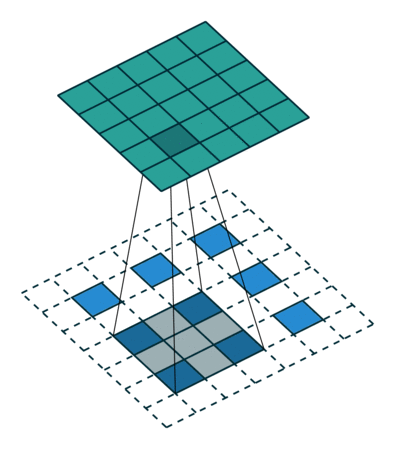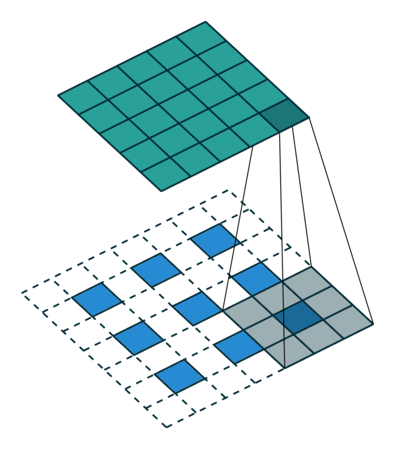
Deconvolution layer는 cnn의 결과물을 원래 이미지의 사이즈와 같이 만들어 주고싶을 떄 주로 사용한다.
CNN에서 convolution layer는 convolution layer(pooling layer)를 통해 feature map의 사이즈를 줄이는데, Deconvolution layer는 이와 반대로 feature map의 크기를 늘려주는 역할을 한다.
원 이미지의 픽셀 사이에 제로패딩을 더해주고 이를 convolution 하는 방식으로 feature map의 크기를 늘려준다.
위 이미지에서 파란색이 input, 초록색이 output인데, 3x3 -> 5x5 로 feature map의 사이즈가 커진 모습을 볼 수 있다.
본 deconvolution은 deconvolution 방법 중 하나인 Bed of Nails Unpooling의 방법이고, 여러가지 deconvolution 방법에 대해 설명하겠다.
Deconvolution의 방법에는 pooling에 대한 deconvolution과, convolution에서 stride에 의해 발생하는 size 감소에 대한 deconvolution이 있다.
Pooling에 대한 Deconvolution의 세 가지 방법
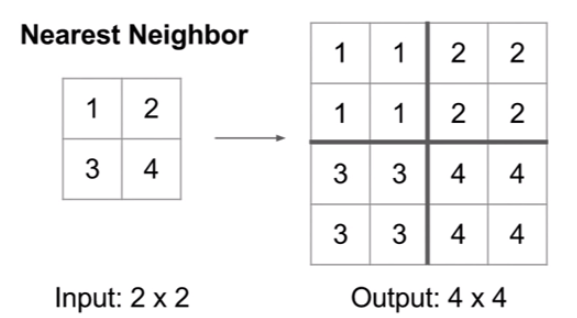
1. Nearest Neighbor Unpooling
2x2를 4x4로 복원 시킬 때, 같은 값으로 복제함
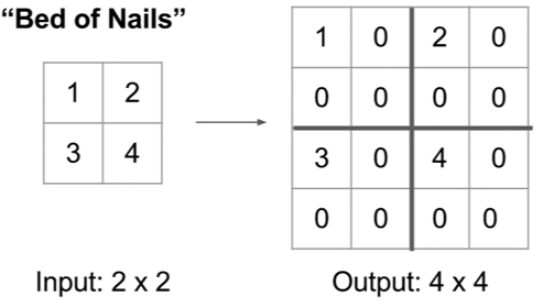
2. Bed of Nails Unpooling
2x2를 4x4로 복원 시킬 때, 그 값만 저장하고, 나머지는 0으로 만듦
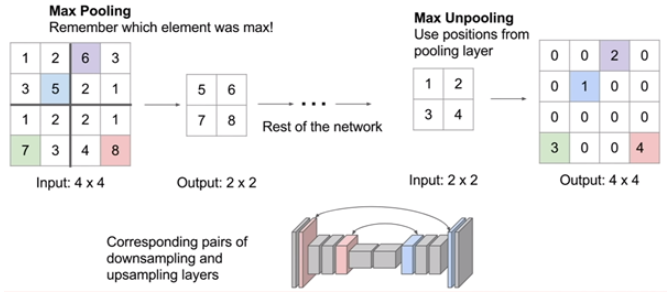
3. Max Unpooling
앞선 Max Pooling layer에 대하여, max pooling 된 위치를 기억하고, 그 위치에 값을 복원한다.
ed of Nails Unpooling에 비해서 정보 손실을 방지할 수 있다.
타 Deconvolution 방법에 비해 별도의 메모리를 필요로하지만, CNN에서 매우 작은 비율이므로 아무런 상관이 없다.
Stride 에 대한 Deconvolution의 방법
Transpose Convolution
Padding을 주지 않았다면, 컨벌루션을 계속할 수록 feature map의 사이즈는 감소 할 것이다.
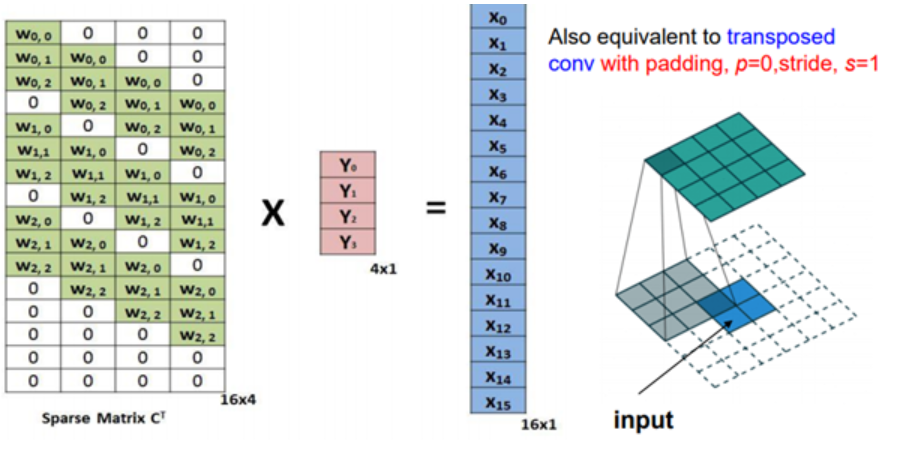
이 때 convolution layer를 알고 있다면, 2x2 output으로부터 4x4 크기의 이미지를 복원 할 수 있을 것이고 방법은 다음과 같다.
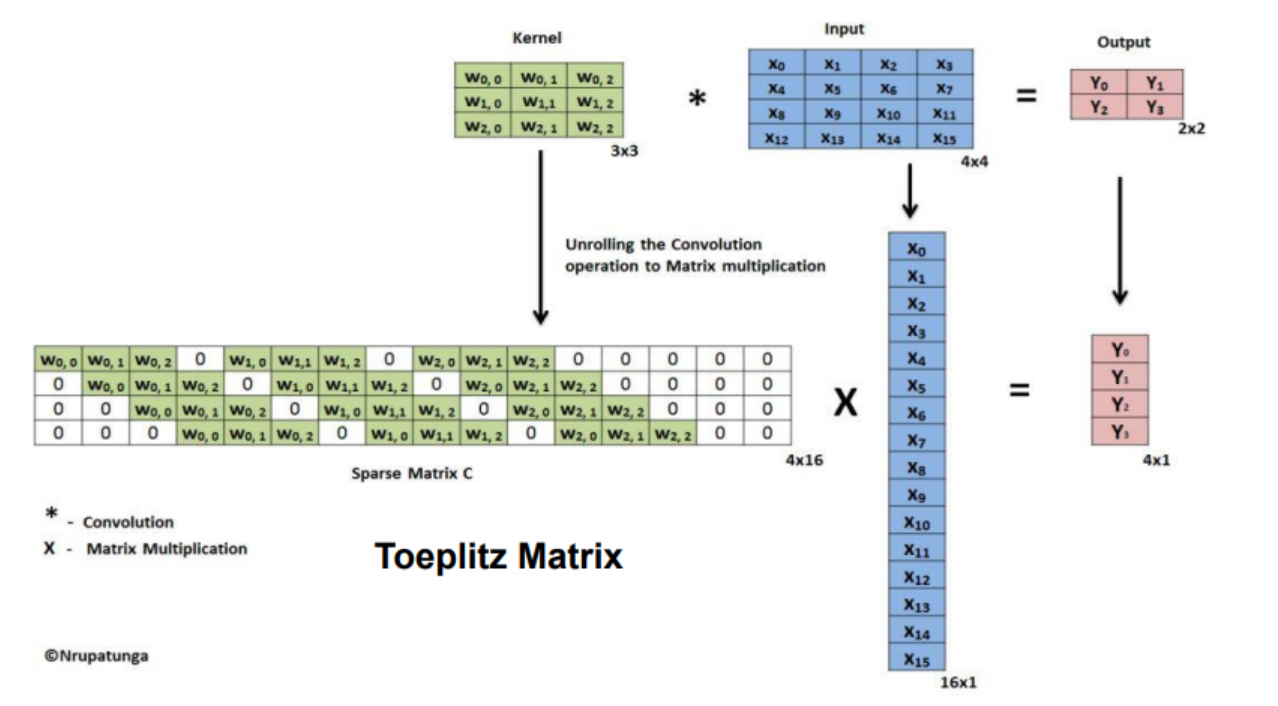
3x3 행렬(kernel) 을 4x4(input image)와 연산하기 위한 꼴로 4x16 matrix로 바꾸고 , input은 16x1 matrix로 바꾸었을 떄 output은 4x1의 matrix가 나옴을 볼 수 있다.
이 떄 3x3 커널을 4x16으로 바꿔준 꼴을 transpose 해주어 16x4 꼴로 바꾸어 주고 이를 output인 4x1 matrix와 행렬곱 했을 때 원본 input인 16x1 꼴이 나온다.
이 떄 convolution maatrix의 weight 들은 원본 이미지의 모습과 가까워 지도록 학습한다.
Pretraining and Fine tuning
Transfer Learning은 이전에 사용되었던 모델의 정보를 입력받아 새로운 모델을 학습하는 것을 뜻한다.
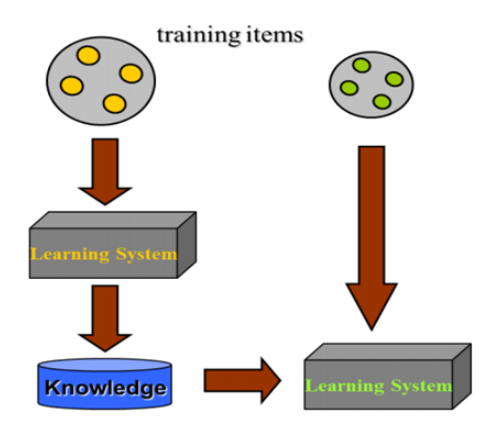
이전에 사용되었던 모델을 pre training이라 하고, 이를 활용해 새로운 모델을 학습( weights를 업데이트)하는 과정을 fine tuning이라 한다.
Fine tuning에는 4 가지 유형이 있다.
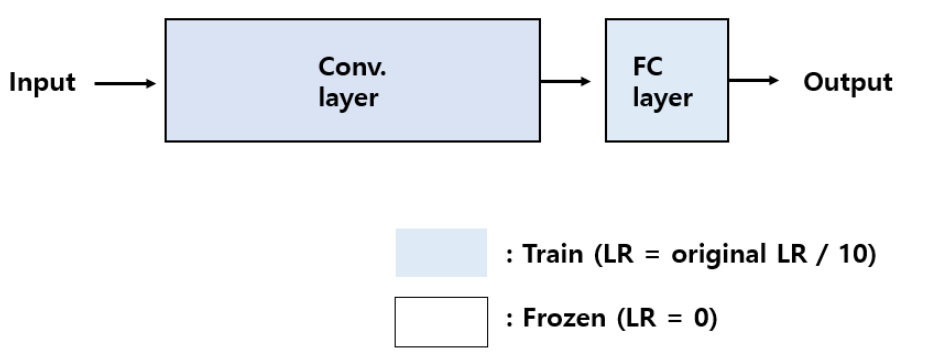
1. Small dataset and similar to the pre-trained model`s dataset
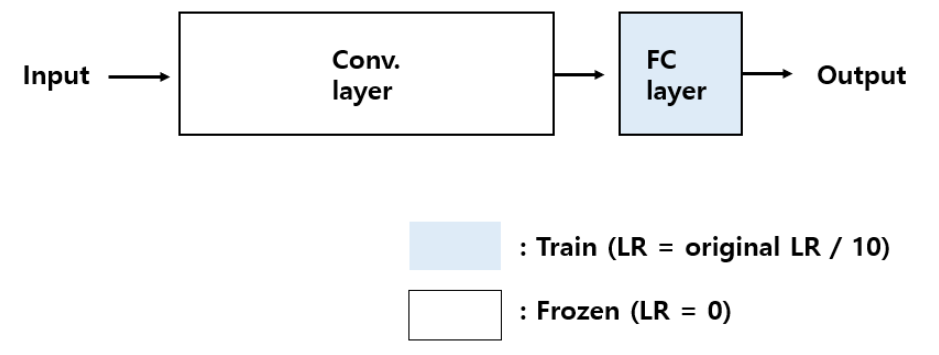
첫 번쨰 경우는 데이터셋이 적지만, 기존에 pre-trained 된 데이터 셋과 비슷한 특징을 가지는 경우이다.
데이터가 적기 때문에, 전체 네트워크에 대하여 Fine-tuning을 하면, over-fitting 문제가 발생하고, 따라서 Fully connected layer에서만 Fine tuning을 진행한다(class 개수만 추가).
Conv. layer에 대해서 학습을 막기 위해서 learning rate를 0으로 주고, 학습하는 층에 대해서는 learning rate를 기존에 pre-trained 된 네트워크의 learning rate의 1/10의 값으로 사용합니다.
왜냐하면, 만약 높은 값의 learning rate를 사용하면, 기존에 있던 정보들은 새로운 데이터 셋에 맞춰서 새로 업데이트 되기 때문에, pre-train 하는 이유가 없어지기 때문이다.
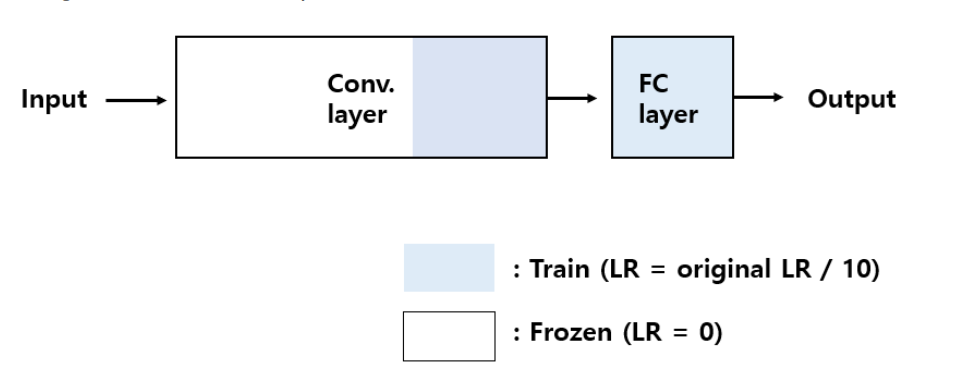
두 번째는, 데이터셋이 충분하고, 기존에 pre-trained 된 데이터 셋과 비슷한 특징을 가지는 경우이다.
이때는 데이터가 충분히 있기 때문에 Conv. layer에 대해서 Fine-tuning을 진행해도 over-fitting의 위험이 없다.
데이터셋이 fine tuning 할 데이터와 유사하기에 fine tuning을 진행할 필요는 없고, 몇 개의 레이어에서 lr을 1/10으로 하여 학습을 진행한다.
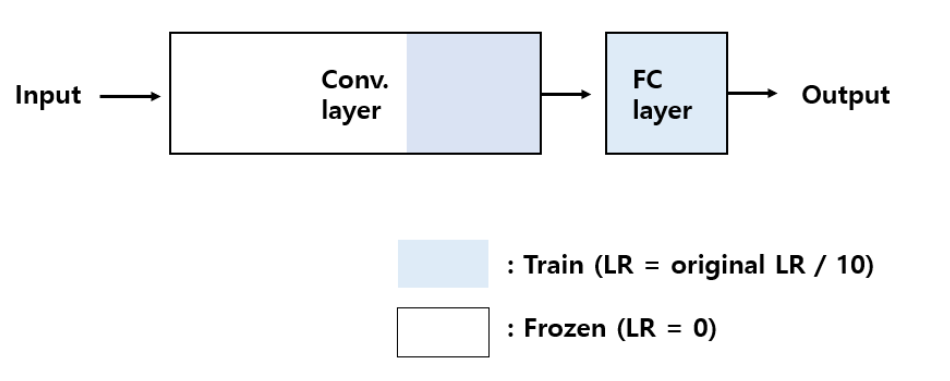
세 번째는, 데이터셋이 충분하고, 기존에 pre-trained 된 데이터 셋과 다른 특징을 가지는 경우이다.
이 때, 데이터 셋에서 차이가 있으므로, 적은 Conv. layer를 Fine tuning 하면은 좋은 학습효과를 낼 수 없다.
데이터셋이 충분하기 때문에 전체 Conv. layer를 Fine tuning 해도 over-fitting문제가 크게 발생하지 않는다.
영근이 형이 하는 task. coco dataset(33만장) + UAD(8만장). 전체 coco dataset(클래스 여러개)에서 차에 대한 feature만 뽑으므로
네 번째는, 데이터셋이 부족하고, 기존에 pre-trained 된 데이터 셋과 다른 특징을 가지는 경우이다.
데이터 셋에 차이가 많기 때문에, 적은 layer를 Fine tuning하기에는 학습효과가 부족하고, 많은 layer를 Fine tuning하기에는 적은 데이터셋에 의해 over-fitting 문제가 발생한다.
이 경우, 따라서 적당한 양의 layer만 Fine tuning을 진행해야 한다.
영근이 형
Efficient dat 을 사용한 coco dataset의 pretrained data의 feature 을 뽑는 단 까지만 사용하였다.
(feature 을 뽑는 단 이란, 클래스 갯수를 정해줄 수 있는 Fully connected layer 이전의 convolution layer 단을 의미하는데, 영근이형이 하는 task는 오로지 차 클래스 1개만 찾는 task이므로 Fully connected layer 전 단 까지만 사용)
이후 coco dataset (33만장) + UAEDETRAC(8만 장)에 대해, 기존 pretrained data로 받은 weight에 추가학습을 LR 0.0001로 진행하여 에폭을 돌렸다.
이 과정에서 파라미터가 업데이트 된다.
pretrained data는, 사용하는 모델에 따라 많이 다르다고 한다.
각 모델별 mAP를 보면 쉽게 가늠 가능할 것이라 생각된다.
Subscribe via RSS