
Realtime multi-person 2d pose estimation using part affinity fields 논문 리뷰
by
본 논문은 여기에서 확인하실 수 있습니다.
Abstract
본 논문은 Bottem Up 방식으로 관절의 키포인트를 먼저 감지후, 포인트간의 연결을 통해 매체 내의 사람의 모션을 인식한다.
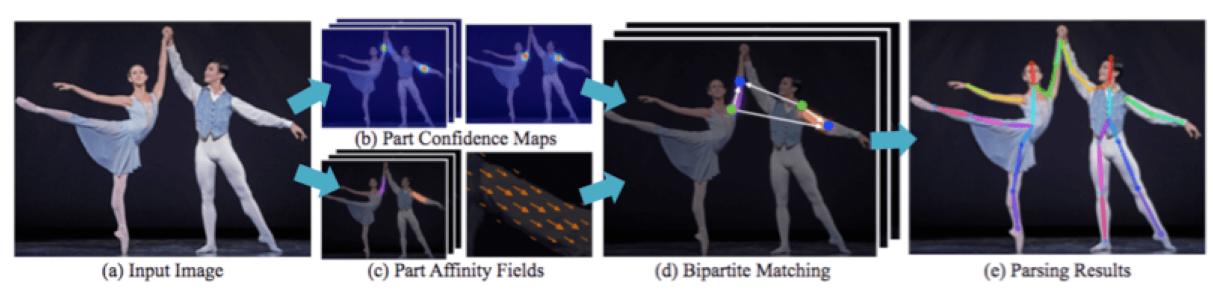
전체적인 flow는 다음과 같다.
(a) : 이미지의 입력.
(b) : Confidence map, 픽셀 단위로 이미지 내 관절의 키포인트에 대한 confidence 해당 픽셀에 인코딩.
(c) : Affinity fields, 신체 내의 2D vector를 해당 픽셀에 인코딩. 2D vector는 어깨에서 팔꿈치, 골반에서 무릎과 같은 벡터를 의미한다.
(d) : Bipartite matching, (b)에서 얻은 해당 픽셀의 관절 키포인트 confidence와, (c)에서 얻은 픽셀의 2D vector를 연관지어, 하나로 일치시킴.
(e) : (d)에서 얻은 결과물을 합쳐 각 신체부위를 구성
Bottom up 방식
Human pose estimation에는, Top down 방식과 Bottom up 방식이 있다.
Top down 방식

Top down 방식은 큰 객체를 먼저 감지한 후 객체 내 작은 객체를 감지하는 방식이다.
Human pose estimation에서는, 사람을 먼저 감지한 후 각 사람의 자세를 추정하는 방식이다.
문제점으로는, 사람을 감지하지 못하면 자세 추정 자체가 불가능하다.
Bottom up 방식

Bottom up 방식은 작은 객체를 감지한 후 그 객체들을 큰 객체로 연결하는 방식이다.
Human pose estimation에서는, 관절과 같은 작은 객체를 감지한 후 이를 서로 연결해 사람의 자세를 추정한다.
문제점으로는, 감지된 관절을 매칭할 수 있는 조합이 매우 많아서, 시간과 정확도를 높이는게 어렵다는 것이다.

한 사람에게 17개의 관절을 감지하여 매칭한다고 할 때, 30명의 사람이 프레임 안에 있을 경우 1.3 x 10^5 라는 연산량이 나오게 된다.
본 논문에서는 알고리즘의 개선을 통해 연산량과 정확도를 개선했고, 알고리즘의 주 내용은 다음과 같다.
-
작은 객체인
관절감지 ->관절+2D vector(신체 부위간 연결관계)감지 -
위
2D vector를 학습을 통해 개선할 수 있는 필터로 하여, 성능 향상
관절 + 2D vector(신체 부위간 연결관계)가 감지된 모습은 아래 그림을 통해 알 수 있다.
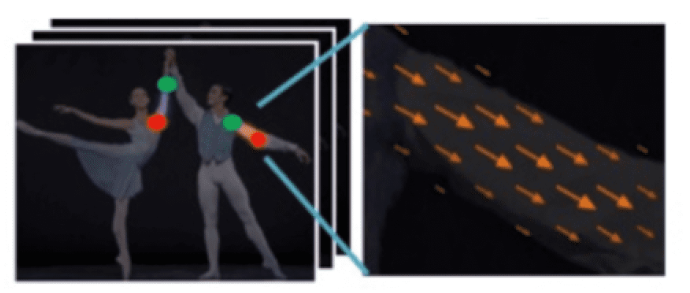
본 알고리즘을 통해 논문에서는 사진 1장에 대해 0.005초에 처리가 가능했다고 한다.
Methods
Method는 논문에 나와있는데로,
Simultaneous Detection and Association,
Confidence Maps for Part Detection,
Part Affinity Fields for Part Association,
Bipartite Matching 순으로 작성하겠다.
Simultaneous Detection and Association
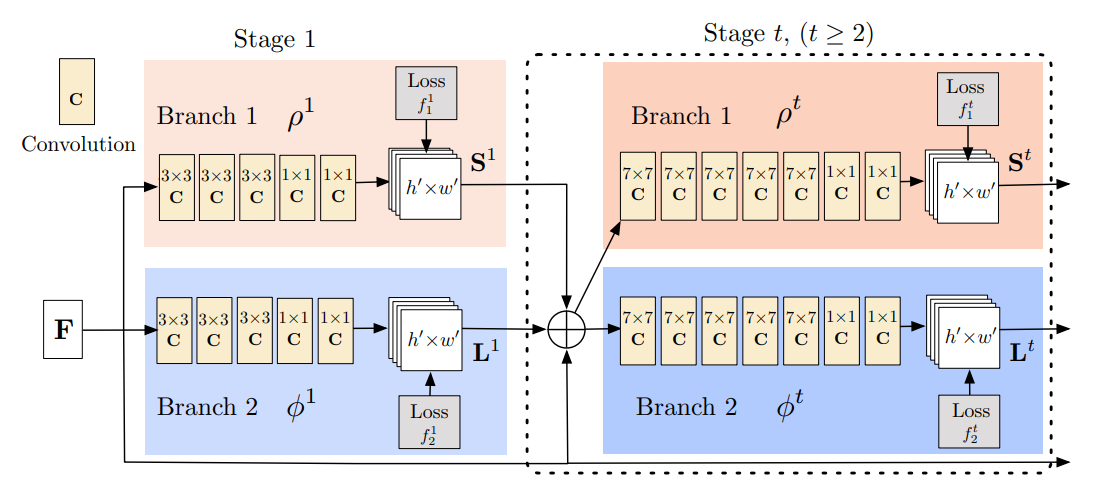
이미지를 입력받아, Confidence map과 Affinity fields를 탐지하는 과정을 보여주는 그림이다.
10 layer VGG-19 모델에서 뽑아온 feature를, architecture의 input으로 준다.
그리고 Confidence map 생성과, Affinity fields 생성을 동시에 진행하고 그 두 branch의 묶음을 한 stage로 정의한다.
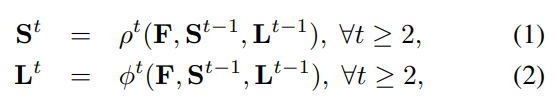
위 수식은 각 branch는
F(원본 이미지의 feature) + S^t-1(이전 stage에서의 confidence map) + L^t-1(이전 stage에서의 Affinity fields)를 input으로 받는다 라는 의미이다.
좀 더 자세히 설명해 보면 VGG19의 output으로 나온 모델은 4번의 풀링을 커친 512채널의 (14,14,512)의 shape을 가질것이다.
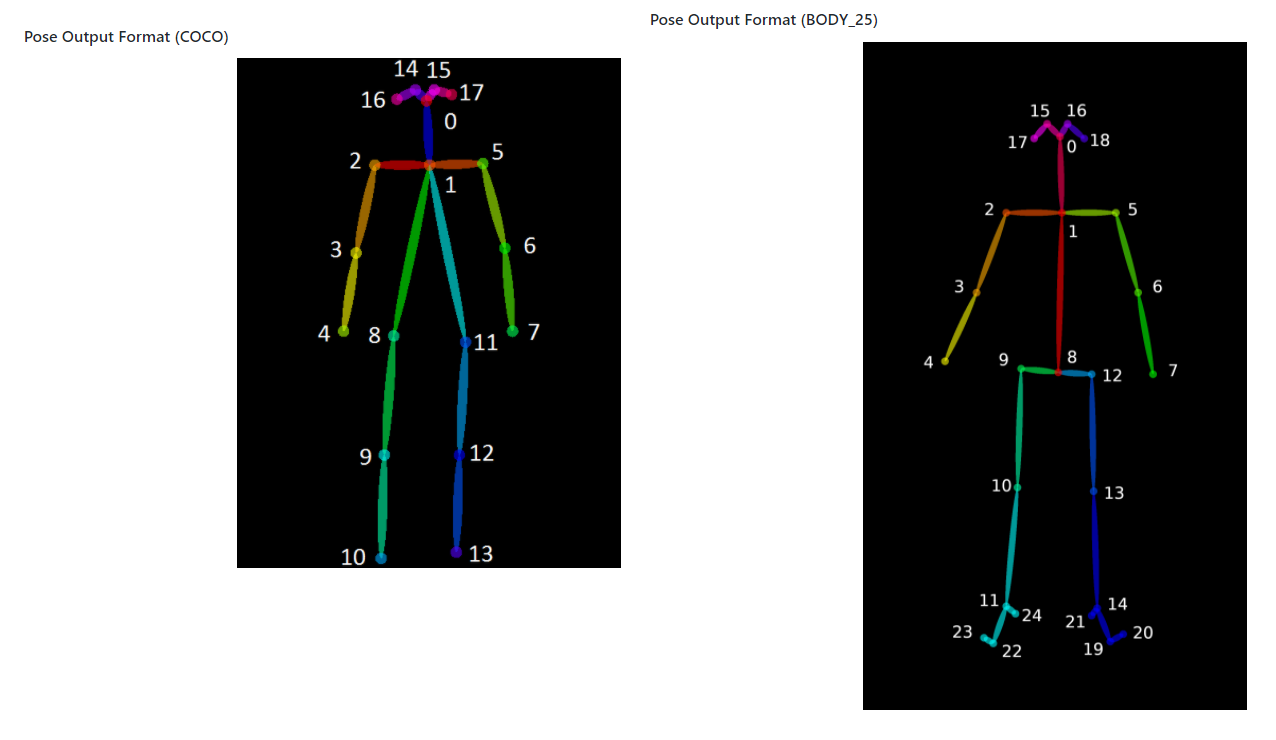
이를 input으로 받아 stage 1의 confidence map에서는 coco dataset 기준(keypoint 18개) 18개의 채널에 대해 convolution 해주어, (14, 14, 18)의 shape을 만들어준다.
예를 들어 채널 1은 왼쪽 손목 feature 의 채널이고 채널 2 는 왼쪽 발들 feature 채널인 식이다.
마찬가지로 stage 1의 affinity fields에서는 (14, 14, 17)의 shape을 만들어준다.
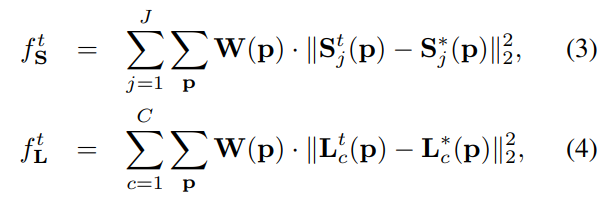
위 수식은 각 stage에 해당하는 S, L 의 loss를 나타낸 것이다.
S, L은 각 confidence map, affinity vector field의 ground truch를 나타낸 것이고, 각 stage에서 예측한 S, L에서 L2 distance를 취해준 것을 볼 수 있다.
W(p)는 binary mask인데, image location p 에 annotation이 없으면 W(p) = 0 을 해주는 식으로 true positive를 제외한 경우를 0으로 해주기 위해 사용했다.
여기서 Stj(p)에 해당하는 값은, 픽셀 좌표가 아닌 해당 픽셀의 confidence 수치(0 or 1)라고 이해했다.
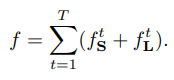
최종 Loss식은 위와 같고, 아래에 stage 를 돌며 annotation이 더 정확해지는 모습을 볼 수 있다.
Confidence Maps for Part Detection
Confidence maps을 찾는 과정을 좀 더 자세히 살펴본다.
Confidence map으로 추출하는 keypoint의 개수는 사용하는 dataset에 다른 영향을 띈다.(추후 나올 벡터 개수 또한 다르다.)
Confidence map은 특정 관절이 각 픽셀 location에 존재하는지에 대한 belief이다.

사진을 보면 자홍색은 머리, 민트색은 무릎 등 픽셀단위로 예측한 모습이다.
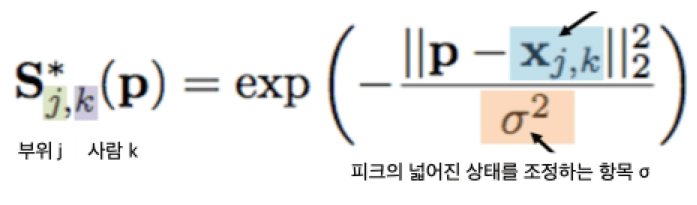
x는 ground truth이고, j 는 해당 관절 index(1 일때 무릎, 2일때 어깨 등), k는 사람 index(1일 때 철수, 2일때 영미 등)을 의미한다.
x는 ground truth좌표이고, s*jk(p)는 p위치에서의 confidence 수치이다.
p가 x에 가까울수록 s*jk(p)이 peak에 다다르는 모습을 보인다.
예를 들어 해당 p가 ground truth이면 individual confidence maps S*jk값이 peak값인 1을 가질것이고, p가 ground truth 값이 아니라면 피크에서 먼 값(0 ~ 1 사이)이라 생각할 수 있다.
따라서 이를 (3)번식에 대입해 보면, Stj(p)는 0 또는 1 값을 가질 것이고, s*j(p)값이 1을 갖는 p값을 찾아(loss가 줄어드는 쪽으로) iteration을 돌며 업데이트 될 것이다.
마지막으로 각 채널들을 합치는 과정에서는 non-maximum suppression 기법을 이용하여, 한 채널에 모든 채널에 대한 정보가 나타나도록 하였다.
Part Affinity Fields for Part Association

각 관절의 키포인트를 연결하는 경우의 수는 매우 많고 이를 고려하여 연결하는 것도 어려운 작업이다.
기존의 방법 (그림 b)는, 각 pair에 중간점을 만들어 또다시 part detection을 수행하여, 그 pair가 한 객체에 맞나 검증하는 방법이었다.
하지만 이 방법은 오로지 좌표을 이용한 연산이기에 각 좌표의 연관관계는 고려하지 않는 한계점이 있었다.
이 한계점을 보완한 기법이 본 논문에서 나온 part affinity 기법이다.
Part affinity는 각 limb(팔 다리 등)의 vector field를 뜻한다.
그렇기에 각 limb(머리를 제외)는 2개의 body part keypoint로 구성된다.
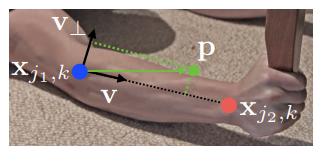
위 사진은 limb c(오른쪽 상완)이고 x(j1,k) 와 x(j2,k)가 limb를 이루는 두 keypoint 이다.
여기에서 p 가 limb c에 놓여있다면, L*(c, k)는 j1, j2 사이의 unit vector일 것이다.
그리고 point C에 대한 다른 포인트들의 value는 0이 될 것이다.

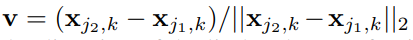
위 수식은 k 사람의 limb c 에 대해 point p 가 limb c 위에 있으면 v 이고, 아니면 0임을 나타낸다.
v는 limb의 방향을 나타내는 단위 벡터를 의미한다.
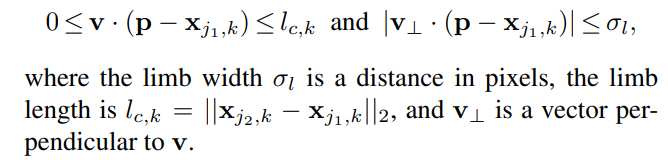
따라서 limb 위의 점의 범주에 속할수 있는 점은 다음 두 조건을 모두 만족해야 한다.
-
두 부위(x(j, k), p) 사이 선분의 거리가 limb의 길이보다 작다.
-
두 점 사이 서분의 거리가 임계값인 시그마(폭) 보다 작아야 한다. (이해 x)
(4)번 식을 이제 이해 할 수 있다.
-
이미지에 대해 두 ground truth x(j1, k), x(j2, k)를 통해 limb를 생성한다.
-
포인트 p에 대해 L*(c,k)(p)에 해당하는 단위벡터 v, 아닌점은 0으로 잡는다.(따라서 p는 limb위에 떠다니는 수많은 점들 즉 벡터가 될 것이다.)
-
(4)번 식인 L(t,c)(p)값이 p에 가까워지도록, 즉 loss가 줄어들도록 iteration을 돈다.
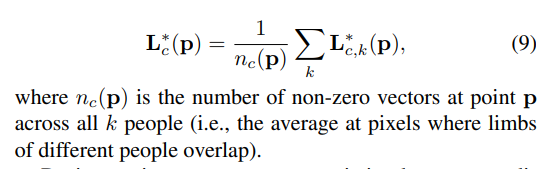
위 식은, L*(c)(p)에 대해서 포인트 p 가 두 개 이상 존재 할 때, 즉 중첩될 때 p 점들이 이루는 벡터들의 average 벡터로 반드는 식이다.
Bipartite Matching

위 식은 한 key point와 다른 keypoint 사이의 방향을 선적분하여 부위간의 확실함을 산출하는 식이다.
산출된 값들중 수치가 가장 높은 값이 두 keypoint간의 최종 벡터가 되는 형식이다.
솔직히 이해 못했다.
Subscribe via RSS