
Capstone-1 주제 선정 : StyleGan
by


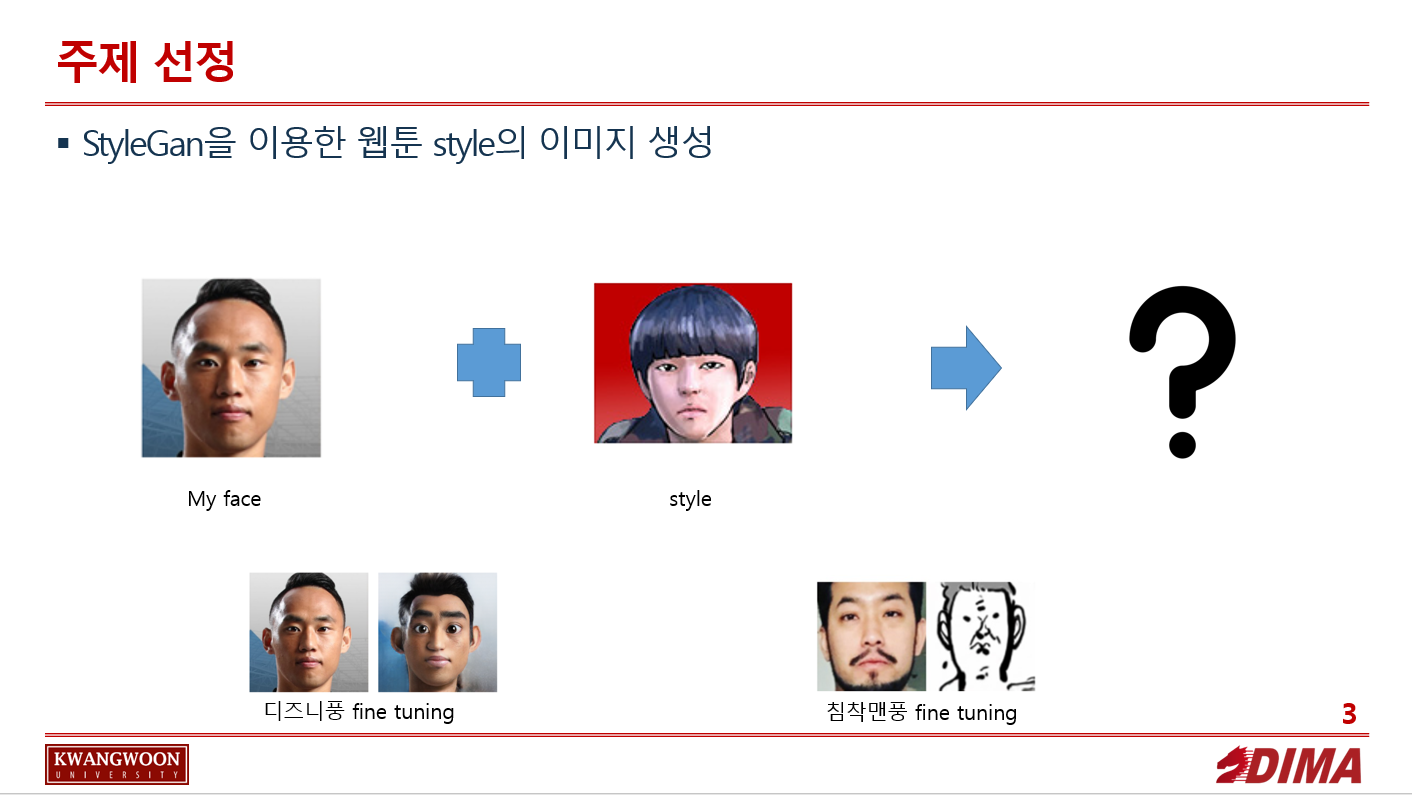




이말년 Gan
StyleGan 기반으로 만든 이후, 각종 기법 추가
Transfer Learning : ImageNet과 같은 대량의 사진으로 Pre-training 이후 약 500장의 웹툰 사진을 통해 Fine-tuning

이와 같이 500장을 crop 하여 사용.
결과 :

CRAN-based cartoon super-resolution model : crop 한 이미지가 너무 작으므로, 딥러닝 방식의 upscaling , 256x256으로 size upscale
Toonify yourself
마찬가지로 디즈니사 이미지 300장을 통해 train
StyleGan1 기반
결과 :


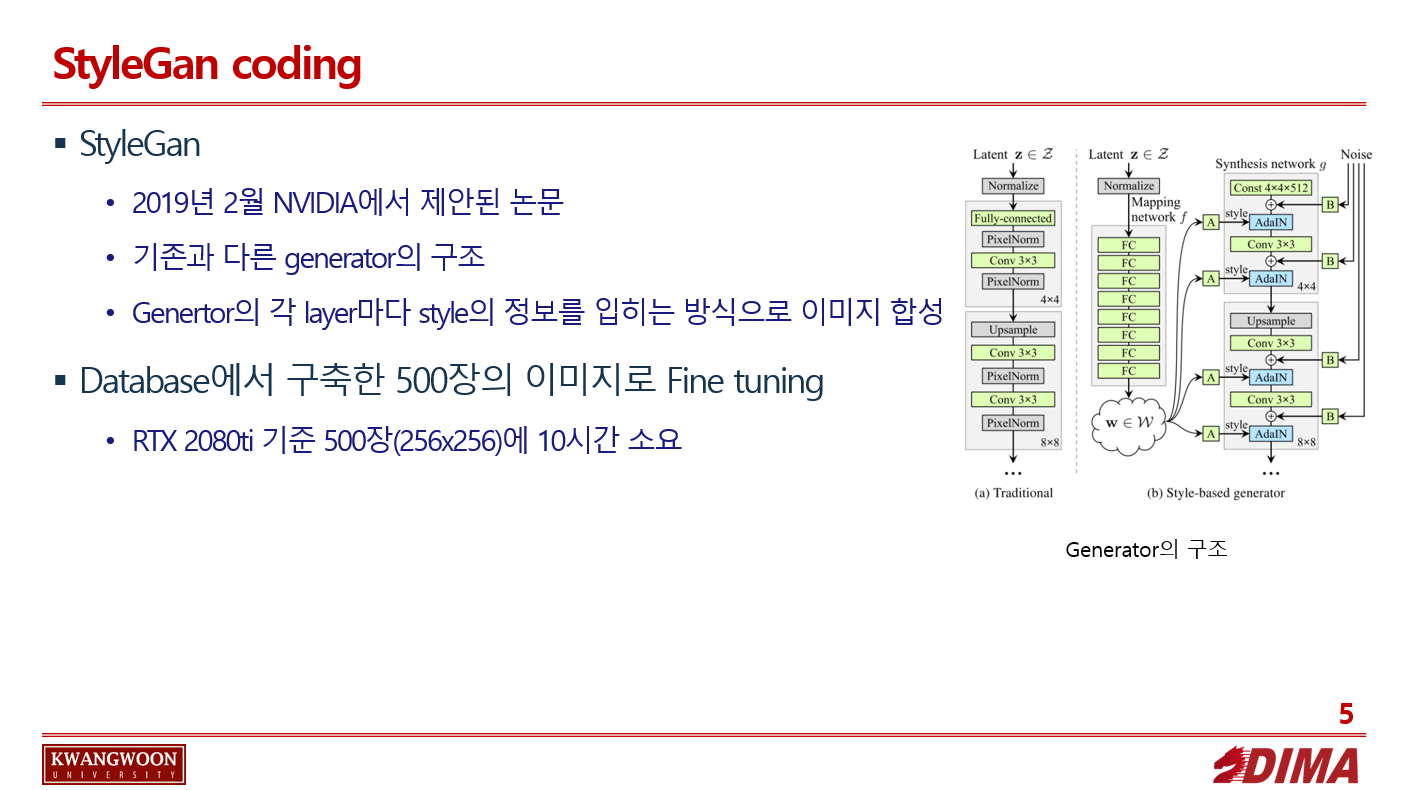
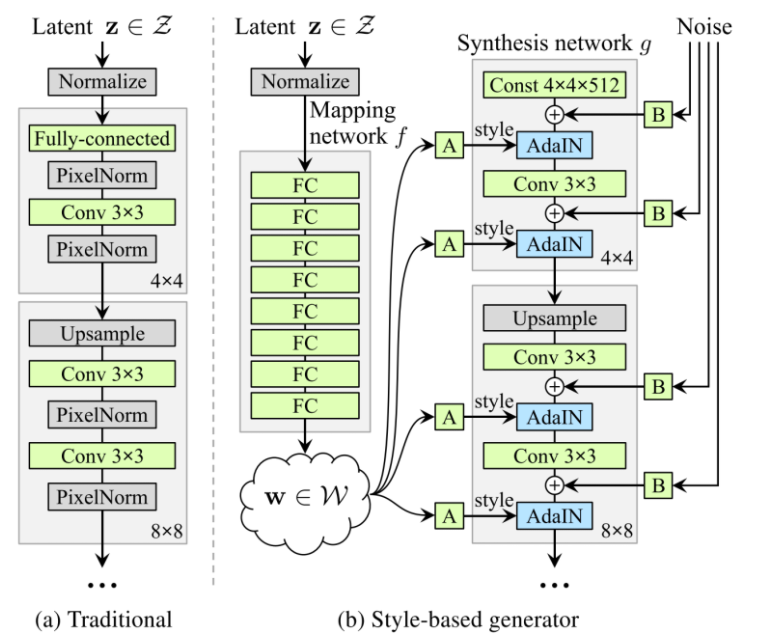
StyleGan
여기 읽어보기
요악 : 19년 2월 NVIDIA에서 제안된 논문
-
기존과 다른 generator의 구조
-
genertor의 각 layer마다 style의 정보를 입히는 방식으로 이미지 합성
나의 구현 방향
방향 : 다른 웹툰 도메인 (ex : 복학왕)등의 이미지를 crop 하여 dataset으로 넣어준 후 fine - tuning

+
구현 중 문제점들이 많을 것이라 생각되므로, 문제점 해결 및 좀 더 나은 결과를 얻는 항뱡으로 연구 할 계획.
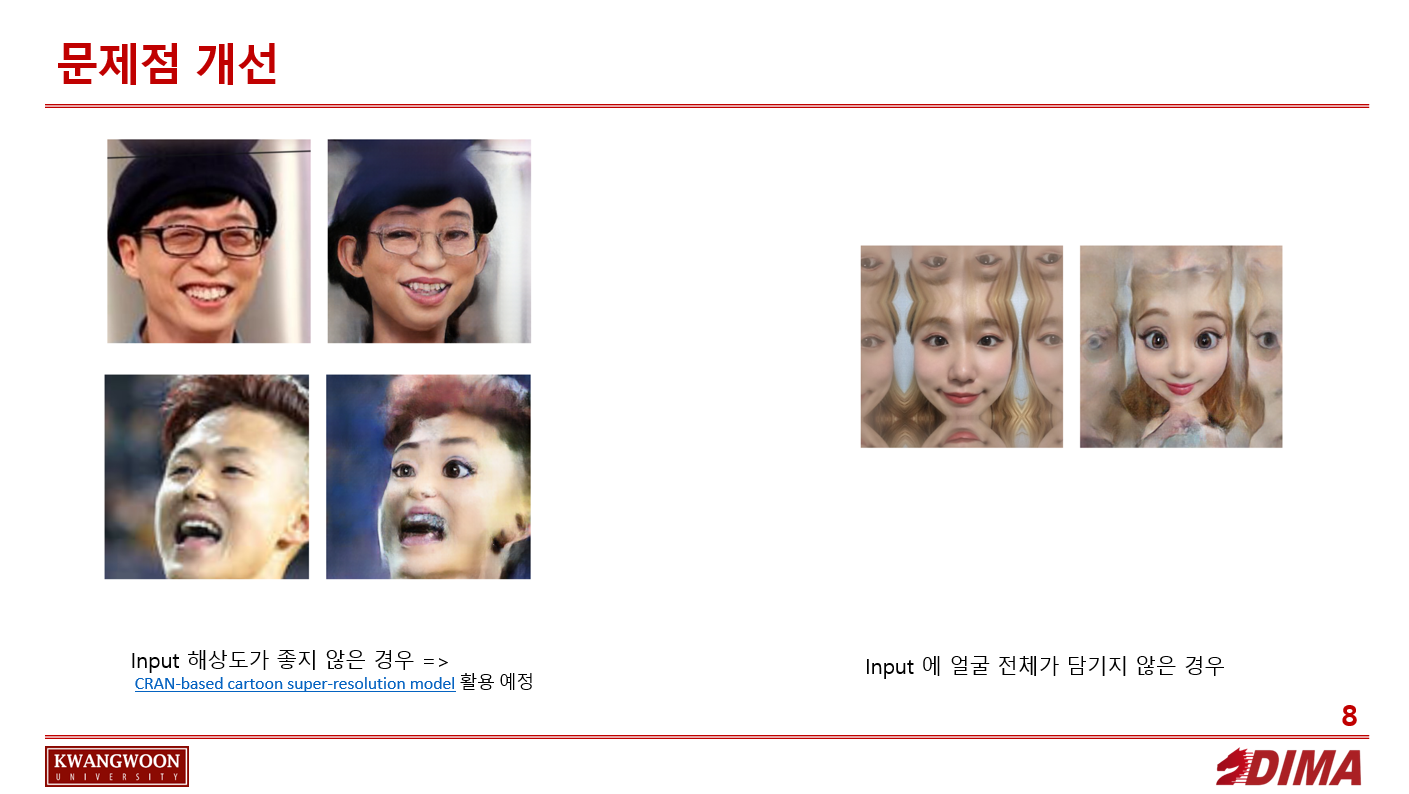
문제점 :
해상도 저하에 따른 bad result

얼굴 전체가 담기게 crop 되지 않아 윗 부분이 자연스럽지 않은 경우

링크
NVIDIA 사에서 만든
Toonify yourself - 코드 (리눅스 중심, TF1 기반)
Subscribe via RSS