
Image Style Transfer Using Convolutional Neural Networks 논문 리뷰
by Dongkyun kim
본 논문은 여기에서 확인하실 수 있습니다.

Abstract
-
본 연구는 이미지 내에서 객체에 해당하는 content와, 전반적인 화풍을 담당하는 style을 분리하여, 이를 transfer 하도록 한 연구이다.
-
기존에는 semantic information을 잘 담은 representation을 찾지 못해 이미지의 style/content 분리가 힘들었다.
-
CNN의 발달로, objection recognition을 통해 얻은 high level information을 잘 표현할 수 있게되어, style/content 분리를 잘 할수 있게 되었다.
Intro
기존의 style transfer 연구는 texture transfer에 국한된 non-parametic problem이었다.
Target image의 semantic information까지 추출하여 transfer하는게 진정한 style transfer이라 말할 수 있지만, 기술력의 부족으로 low level image feature of target만 transfer하였다.
기술의 발달로, high level representation을 통해 semantic 정보까지 잘 담은 style을 content와 독립적으로 transfer할수 있게 되었다.
2.0 Deep learning representation
본 연구에서 feature map을 뽑을 때, VGG19의 normalized 버전을 사용하였다.
이 버전은 16 conv layer, 5 pooling layer, no fcn 으로 이루어진다.
Pooling layer로는 maxpooling 대신 average pooling을 사용하였는데, 이는 성능이 더 좋았기에 사용했다고 한다.
수치상으로 더 좋은게 아니고 good appealing 이었다고 함.
(mean activation의 뜻이 헤깔림)
 각 conv layer, activation을 거친 픽셀당 평균이 1이 되도록 normalize 했다고 한다.
각 conv layer, activation을 거친 픽셀당 평균이 1이 되도록 normalize 했다고 한다.
2.0.1 hierarcy에 따른 style representation, content representation의 이해

Conv layer를 거쳐 나온 content에 대한 representation부터 살펴보자.
밑에 그림 a, b, c, d, e 는 각 conv layer를 거쳐 나옹 representation들을 reconstruct하여 input image와 비슷한 모양으로 구성한 것이다.(conv 반대로 진행하고 평균내었다 생각함)
Higher layer로 갈수록 지엽적인 detail pixel information에 대해서는 부정확한 양상을 보이지만 그 이미지가 담고있는 content에 대해서는 잘 보존된(의미를 잘담은) 모습을 보인다.
따라서 higher layer을 거친 결과(loss에서 추후 사용)물을 수치로써 사용한다.
Style에 대한 representation을 살펴보자.
Style에 대한 information은 gram matrix(texture, style을 잘 설명)을 통해 얻을 수 있다.
Content representation과 달리 모든 level의 conv layer의 output에서 gram matrix를 구하여 loss를 구하는데 사용한다.
Higher level로 갈수록 이미지에 대한 style은 더 잘 담는 반면, 그 이미지의 전체적인 배열, 구조는 뭉게지는(부정확한) 모습을 보인다.
2.1 Content representation
앞서 말했듯이, hierarcy가 higher layer로 갈수록 object(content) representation이 명료해진다.
Lower layer에서 reconstruction을 진행할 경우 exact pixel값을 단지 reproduce(copy)하지만, higher layer에서 reconstruction을 진행하면 어느정도 pixel value outlier은 용인한채 object 그 자체와 arrangement 정보는 잘 살려서 reconstruction한다.
따라서 loss를 구할때는, 최상단에 있는 layer의 output만을 사용한다.
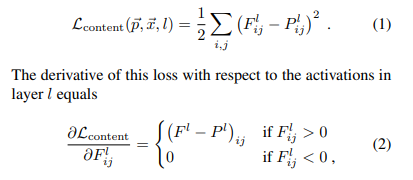
Flij는 input image p arrow가 l번째 레이어단에서 i번째 필터의 j픽셀의 activation된 값이다.
그리고 Plih는 generated image x arrow가 l번째 레이어단에서 i번째 필터의 j픽셀의 activation된 값이다.
마지막 conv layer 단에서, 그 layer단의 모든 필터와 픽셀에 걸쳐 loss를 구해 square error가 최소가 되도록 하는 x arrow를 구한다.(loss를 x에 대해 미분하여 GD 함)
그러면 white noise로 초기화되었던 x arrow가 input image p arrow 의 content를 담은 모습으로 iteration을 돌면서 진화될 것이다.
모델을 학습시키는게 아니라,
학습된 모델(VGG19)을 가지고 해당 input image의 content를 담은 generated image x arrow를 생성하도록 iteration을 도는 것임을 생각하자.
2.2 Style representation
Style represenatation을 이해하기 위해선 gram matrix에 대한 이해가 필요하다.
Gram matrix는, 이미지의 content정보는 뒤로한 채 style(texture)정보만을 잘 나타내는 matrix이다.

N개의 filter 를 가진 layer단에서 Gram matrix는, 해당 수식(3)의 방식으로 구해진다.
Gram matrix의 각 element는, i번째, j번째 filter를 거칫 값들을 1차원으로 flatten하고 내적을 취해준 scalar값이다.
각 element를 모두 구해서 gram matrix를 살펴보면, 이 gram matrix는 공분산 행렬임을 알 수 있다.
공분산 행렬이라 함은 i번째 필터(의 activation)와, j번째 필터(의 activation)의 correlation이 공분산행렬의 i,j번째(j, i)번째 element에 들어간 전치행렬일 것이다.
만약 해당 공분산 행렬과 비슷하게(두 차이가 적도록) 갖도록 이미지를 생성한다면, 그 두 이미지의 스타일 역시 비슷할 것이다.
모든 Element(Filter의 activation을 거친 값들의 correlation들)이 모두 유사할 것이기에)
따라서 해당 논문에서는 style representation을 구할때에는 gram matrix의 차이가 줄어들도록 이미지를 생성하는 방식을 채택했다.
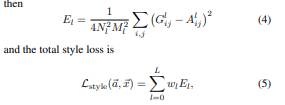
Content representation과 달리 모든 layer에서 gram matrix를 구해 loss를 구한다.
이 때 각 layer단에서 style representation을 생성할 때 가중치를 얼마나 둘건지를 정해주는 weight를 할당이 가능하다.
2.3 Style transfer
이제 2.1에서 구한 content와, 2.2에서 구한 style을 적절하게 mixing한다.
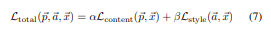
이는 두 loss를 합쳐 구현이 가능하고, 가중치를 주어 어느 loss에 중점을 두어 이미지를 생성할건지 정할 수 있다.
따라서 전체 학습 과정은 다음과 같다.
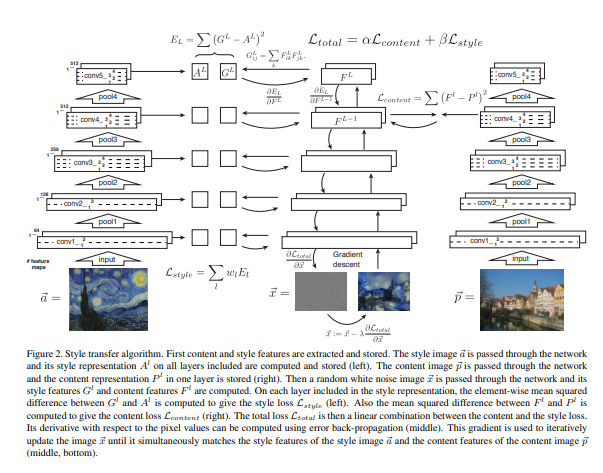
3. Result
Total loss에서 계수 조정

해당 이미지는 2.3에서 알파, 베타값 비율을 달리하여 생성 이미지이다.
content에 중점을 둘수록 style에대한 정보가 작아지고 역도 마찬가지이다.
Cont representation에서 layer단 선택에 따른 결과

중간에 있는 이미지는 content representation에서 2번째 conv단의 output을 사용한 것이고, 밑의 이미지는 마지막 conv단의 output을 사용한 것이다.
2.2에서 말했듯이 2번째 conv단의 output을 사용했을 때에는 detail pixel까지 original image의 content와 거의 일치하여 단지 style이 이미지에 덥혀진 정도로만 보이는데,
마지막 conv단의 output을 사용했을 때에는 style에 적절하게 content가 mixing(건물 휨)되어 좀 더 그 화가의 화풍이 담겨있음을 볼 수 있다.
4. Discussion
아무래도 2016년에 나온 논문이다보니, inference time이 Nvidia K40 GPU로 (512, 512)이미지를 생성하는데 한 시간이 걸렸다고 한다.
그리고 style이나 content에 대해 얼마나 잘 추출하는지 판가름하는 metric 역시 부재하고, 눈대중으로 판가름 하기에 이를 수치화 하기엔 힘들다.
하지만 딥러닝 기법을 이용하여 style transfer를 시도한 논문임에 의미가 있는 것 같다.
Subscribe via RSS