
GAN Code
by

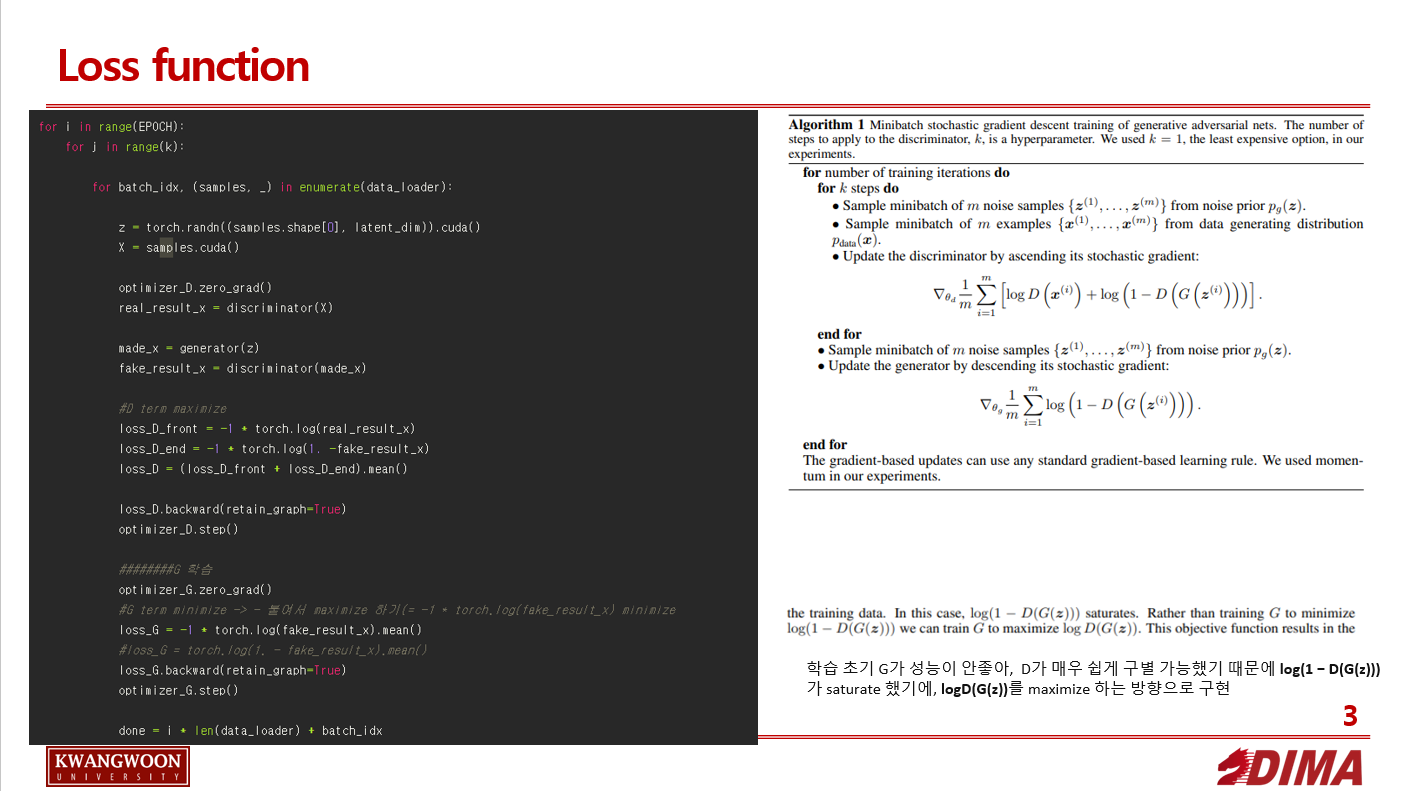

GAN의 Value function
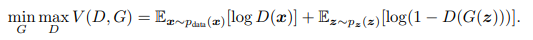
D Ex~pdata는 원본 이미지에서 이미지 1개를 sampling, Ez~p(z)는 p(z)에서 노이즈를 샘플링해와 이미지로 업샘플링 시킨 것이다.
앞 term부터 살펴보면, D는 V를 max가 되도록 한다.
Discriminator가 이미지가 생성된 이미지인지 아닌지를 맞췄으면 1, 못맞추었으면 0값을 가지고, 이 값이 커지도록 즉 답을 더 잘 맞추도록 학습한다.
뒤 term 역시 이미지에 대한 답을 맞췄으면 log(1-x)가 가질수 있는 최대 값인 0을 가져 V를 maximize한다.
G D가 속을만큼 그럴듯한 이미지를 만드는 것이 목표이다.
즉 D(G(z)) = 1이 되도록 학습한다.
이를 식의 뒷 term에 넣어보면 V를 minimize함을 할 수 있다.
학습 부분 구현

을 구현한 부분이다.
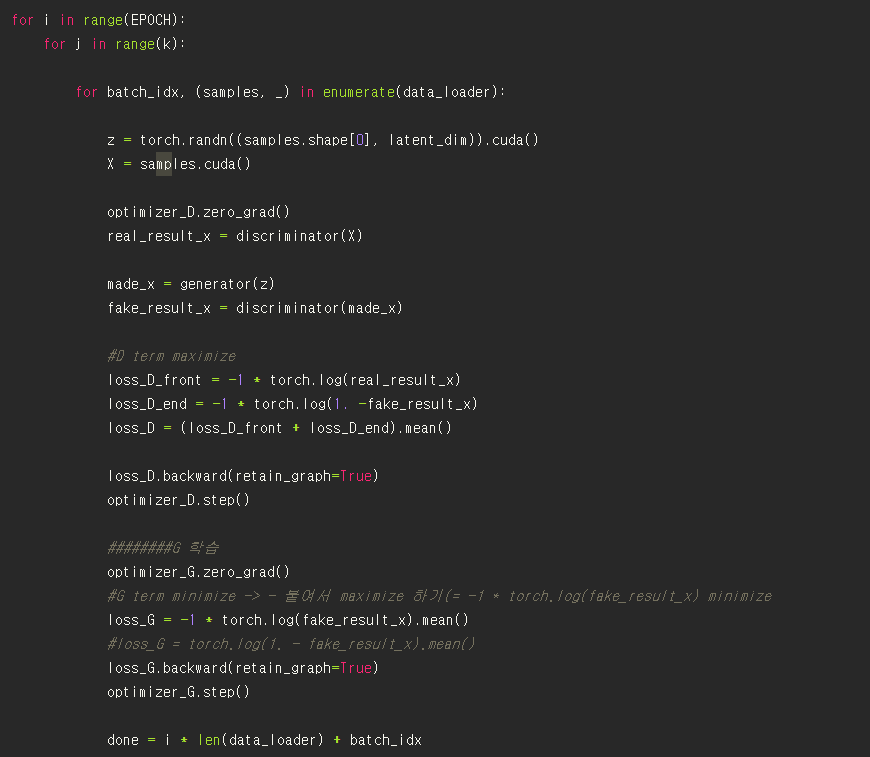
D를 먼저 학습시킨 후(이 때 G의 parameter는 고정), G를 학습시킨다.
위의 term을 살펴 보면, “Update the discriminator by ascending its stochastic gradient” 이므로, loss 함수의 값을 극대화 시키도록 파라미터 값을 찾는다.
이를 코드로 구현할 때에는, loss를 높이도록 설계하기 위해, 기존 식에 -를 달아주어 -(loss)를 감소시키도록, 즉 loss를 증가시키도록 설계했다.
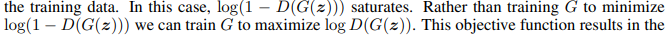
G를 학습 할 때에는, 원래대로라면 log(1 − D(G(z)))를 minimize 하는 방향으로 설계해야 했지만, logD(G(z))를 maximize 하는 방향으로 구현했다.
이 이유는 G가 충분히 학습할 만한 gradient를 주지 못했기에, 즉 학습 초기 G가 거지같아서 D가 매우 쉽게 구별 가능했기 때문에 log(1 − D(G(z)))가 saturate 했기에, logD(G(z))를 maximize 하는 방향으로 학습시켰다고 한다.
loss_D.backward(retain_graph=True)를 통해 backward pass하여 gradient를 조정해 주고,
optimizer_D.step() 을 통해 파라미터 값들을 업데이트 한다.
optimizer_D.zero_grad()를 매 iteration마다 해주는데, backward()를 호출할 때마다 변화도가 buffer에 누적되기 때문에 항상 tensor를 0으로 만들어줘야 하는 필요가 있기 때문이다.
tanh vs sigmoid

논문을 보면
G에선 Relu, sigmoid
D에선 maxout activation, dropout을 썼다고 한다.
sigmoid를 G에 적용하면 결과가 매우 안나왔는데, 오히려 tanh를 쓰면 그래도 어느정도 결과가 나왔다.
maxout activation은 sigmoid 및 Relu로 대체했다.
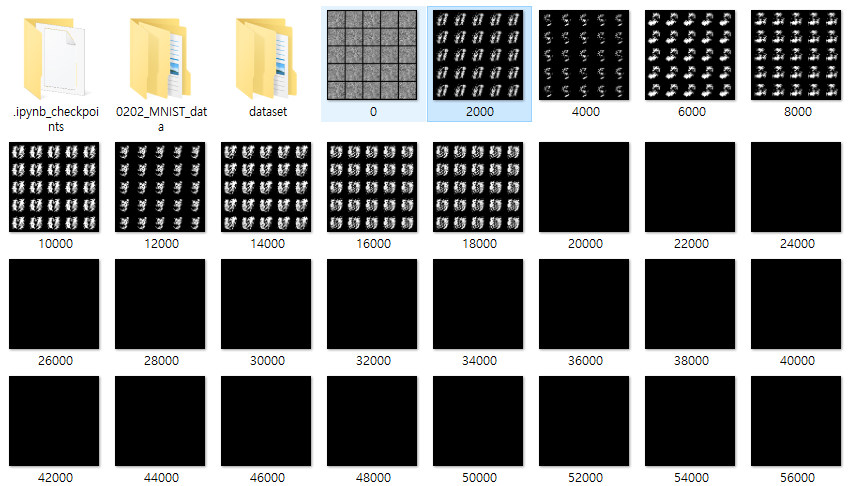 (sigmoid를 썼을 때.. 18000 이상시 loss 가 nan으로 되어 학습 종료)
(sigmoid를 썼을 때.. 18000 이상시 loss 가 nan으로 되어 학습 종료)
 (tanh를 썼을 때.. 상대적으로 숫자가 보인다.)
(+ tanh를 썼으므로 0~1 normalize 과정 필요함.)
(tanh를 썼을 때.. 상대적으로 숫자가 보인다.)
(+ tanh를 썼으므로 0~1 normalize 과정 필요함.)
CODE
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from matplotlib import pyplot as plt
from torchvision.utils import save_image
batch_size = 128
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(1 * 28 * 28, 256),
nn.ReLU(),
nn.Linear(256, 1),
nn.Sigmoid())
def forward(self, img): #한 장의 이미지가 들어왔을 떄 flatten 하여 쭉 나열하고, 모델에 넣음
flattened = img.view(batch_size, -1) #(32, )로 flatten 해준 후 모델에 넣음
output = self.model(flattened)
return output
class Generator(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Linear(100, 256),
nn.ReLU(),
nn.Linear(256, 512),
nn.ReLU(),
nn.Linear(512, 1* 28* 28),
nn.Sigmoid())
def forward(self, input): #input : 100차원 noise
img = self.model(input)
img = img.view(batch_size, 1, 28, 28)
return img
from torch.utils.data import TensorDataset # 텐서데이터셋
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
mnist_train = dsets.MNIST(root='0202_MNIST_data/', train = True, transform = transforms.ToTensor(),
download = True)
data_loader = DataLoader(dataset = mnist_train, batch_size = batch_size, shuffle = True,
drop_last = True)
print(len(data_loader))
print(len(mnist_train))
generator = Generator()
discriminator = Discriminator()
generator.cuda()
discriminator.cuda()
lr = 0.0002
optimizer_G = torch.optim.Adam(generator.parameters(), lr = lr, betas = (0.5, 0.999)) #모멘텀, adaptive term
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr = lr, betas = (0.5, 0.999))
import time
EPOCH = 500
k = 1
latent_dim = 100
start_time = time.time()
for i in range(EPOCH):
for j in range(k):
for batch_idx, (samples, label) in enumerate(data_loader):
z = torch.randn((samples.shape[0], latent_dim)).cuda()
X = samples.cuda()
optimizer_D.zero_grad()
real_result_x = discriminator(X)
made_x = generator(z)
fake_result_x = discriminator(made_x)
#D term maximize
loss_D_front = -1 * torch.log(real_result_x)
loss_D_end = -1 * torch.log(1. -fake_result_x)
loss_D = (loss_D_front + loss_D_end).mean()
loss_D.backward(retain_graph=True)
optimizer_D.step()
########G 학습
optimizer_G.zero_grad()
#G term minimize -> - 붙여서 maximize 하기(= -1 * torch.log(fake_result_x) minimize
loss_G = -1 * torch.log(fake_result_x).mean()
#loss_G = torch.log(1. - fake_result_x).mean()
loss_G.backward(retain_graph=True)
optimizer_G.step()
done = i * len(data_loader) + batch_idx
if done % 2000 ==0:
#img = generator(torch.randn(100)).cpu().detach().numpy()
print(done)
save_image(made_x.data[:25], f"{done}.png", nrow=5, normalize=True)
#print(img.shape)
#npimg = img.numpy()
#plt.imshow(np.transpose(npimg, (1, 2, 0)))
#plt.imshow(img, cmap='gray')
print(f"[Epoch {i}/{EPOCH}] [D loss: {loss_D.item():.6f}] [G loss: {loss_G.item():.6f}] [time: {time.time() - start_time:.2f}s]")
Subscribe via RSS