
Learning Deconvolution Network 논문 리뷰
by
본 논문은 여기에서 확인하실 수 있습니다.
여기를 참고하여 만든 포스팅입니다.
Abstract
해당 논문은 2015년 ICCV에서 발표된 인용 수 2800회의 논문입니다.
PASCAL VOC2012 에서, MS 의 COCO dataset을 사용하지 않고 72.5%의 accuracy를 달성한 것이 특징입니다.
당시 sementic segmentation algorithm(이미지 내 모든 객체의 클래스를 찾는 기법)은 human pose estimation과 같이 structured 된 픽셀 단위의 라벨링 작업에서 종종 사용되었다.
Sementic segmentation에서는 기존 CNN구조를 classification을 하기 위해 FCN(Fully Convolutional Network)구조로 바꾸었다.
FCN이 deconvolution시 pixel 단위에서 bilinear interpolation 기법을 사용했다.
bilinear interpolation(이중 선형 보간법)이란, 1D Linear Interpolation 을 2D로 확장 한 것이다.
1D Linear Interpolation은 내분 이다.
주어진 두 점 사이의 거리를 추정할 때, 그 값을 두 지점과의 직선 거리에 따라 선형적으로 결정하는 방식이다.
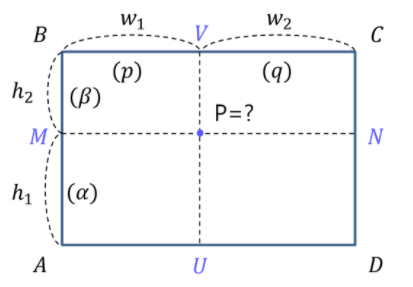
다음은 Bilinear interpolation이다.
x축 방향으로 사각형의 변까지의 거리를 w1, w2, y축 방향으로 거리를 h1, h2라 하고, 알려진 네 점에서의 데이터 값을 A, B, C, D라 할 때, P에서의 데이터 값은 bilinear interpolation에 의해 다음과 같이 계산된다 (단, α=h1/(h1+h2), β=h2/(h1+h2), p=w1/(w1+w2), q=w2/(w1+w2)).
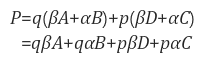
해석해 보면 먼저 (A, B) , (C, D) 를 높이에 대해 내분하고, 나온 두 내분점을 가로축에 대해 내분하는 것이다.
근데 A, B, C, D가 직사각형을 이루지 않고 사다리꼴 과 같은 모양을 이룬다면, 이 사각형을 직사각형 모양으로 warping 후 interpolation 을 수행해야 한다.
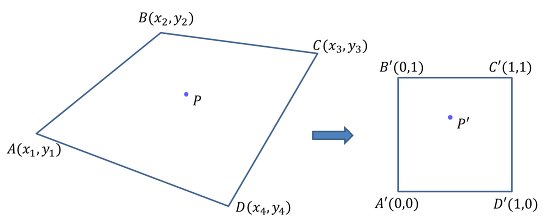
원래 사각형의 네점 ABCD를 A’B’C’D’으로 변환시키는 선형변환(linear transformation) T를 구한 후, 구한 T를 이용하여 P를 변환시킨 P’를 구하고 단위 정사각형에서 bilinear interpolation을 수행하면 된다. (잘 이해 x)
선형 변환 T 만큼을 P에 곱해주고 interpolate 하면 되는 것 같다.
FCN에 기반한 Sementic segmentation은 몇 가지 치명적 단점이 있다.
첫쨰로 network가 기존에 정의된 크기의 고정된 receptive field를 갖는데, 이로 인해 receptive field보다 크거나 작은 물체는 파편화 되거나 mislabeled 될 수 있다.

(a)는 receptive field 크기보다 object의 크기가 커서 물체가 잘린 모습이고, (b)는 object가 너무 작아 background 로 분류된 모습이다.
두 번쨰는 이미지 내 객체의 detail한 구조가 뭉개지거나 없어지는 문제이다.
deconvolutional layer로 들어가는 label map이 너무 coarse(조잡하다, 투박하다?)하고, deconvolution 과정이 너무 간단했기 떄문이다.
FCN은 16 x 16 label map 에서 deconvolution을 거쳐 원본 사이즈로 복원했으므로, 구조가 뭉개지는 것은 당연하다.
아직 작성중..
Subscribe via RSS