
CNN summary
by
CNN의 구조
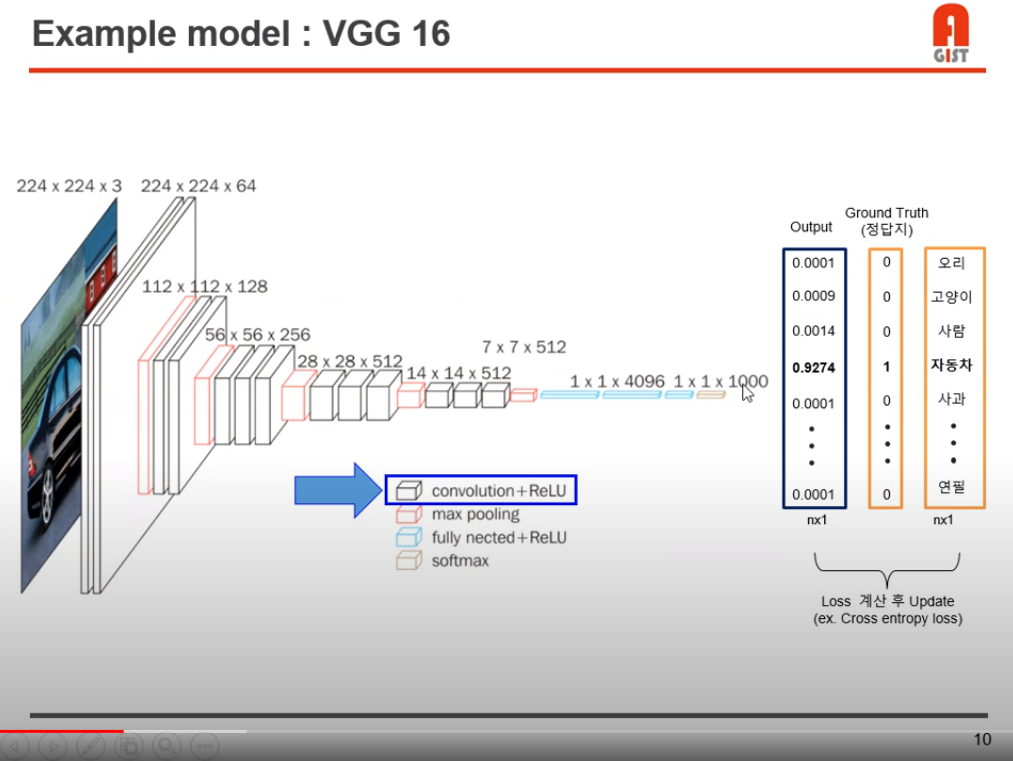
위 그림은 CNN의 구조이다.
대부분의 모델은 위 과정 내에서 레이어, 모델등이 바뀐 구조이지만 input으로 사진이 들어가고, output으로 각 label(class)가 나오는 구조는 통용된다.
채널 수가 3 -> 64 -> 128.. 로 계속 느는 것을 볼 수 있는데, 예를 들어 3 -> 64로 채널 수가 변하는 경우, input 채널 3개에 대해 filter 거치는 연산을 한번씩 총 세 번 해주고 concat한다.
이 연산을 각 filter 에 대해 해주므로 총 64번의 위 과정을 한다.
다음 사진을 보면 이해가 쉽다.
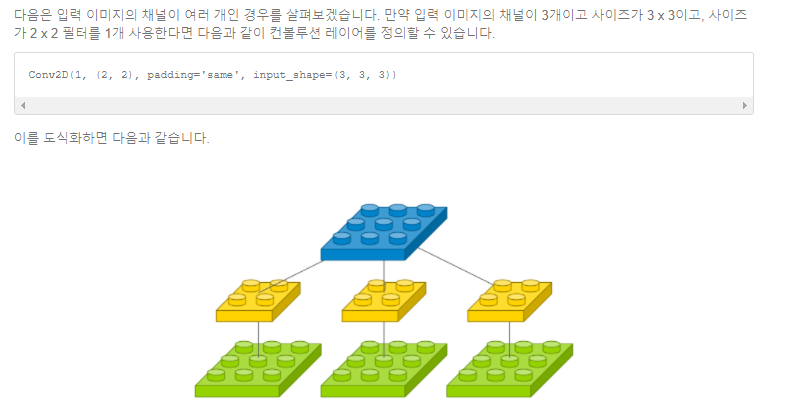
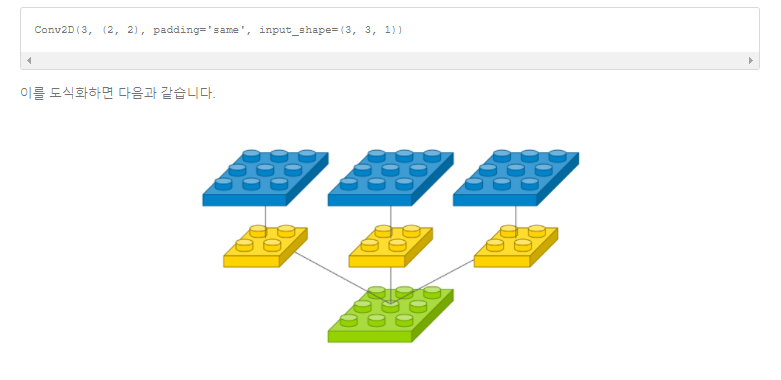
예를 들어 input channel이 3이고 filter 갯수가 1이면, output channel 수는 1이다.
input channel이 1이고 filter 갯수가 3이면, output channel 수는 3이다.
output channel 수는 input channel 수와 같음을 알 수 있다!
Convolution Part
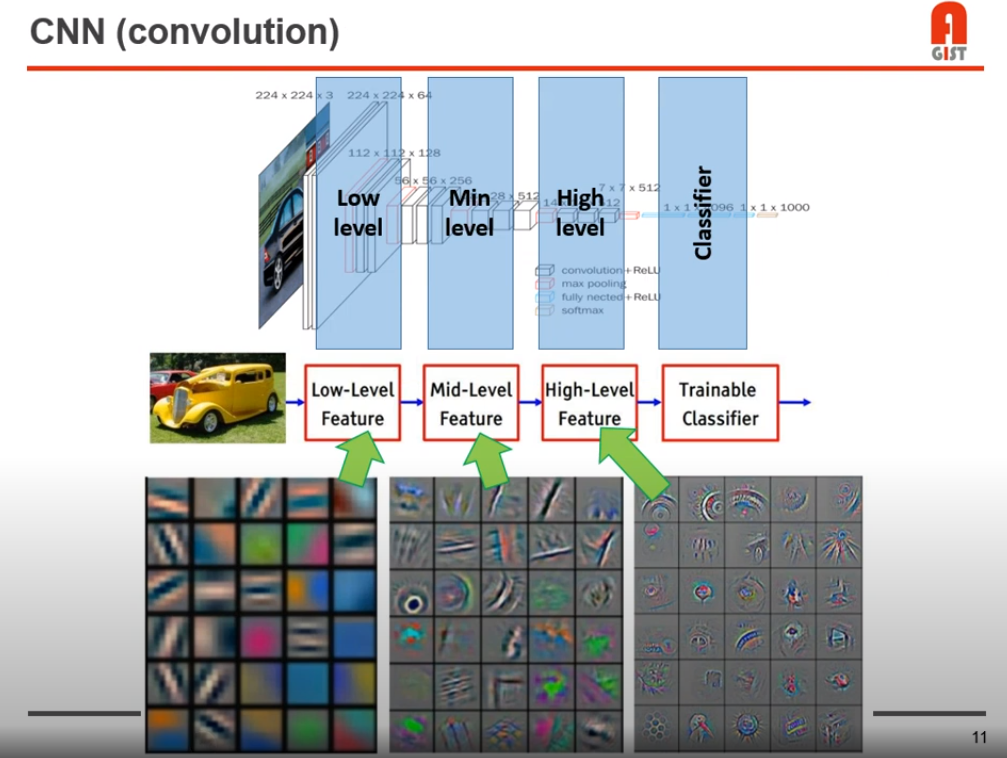
이미지에 대해 feature를 뽑기 위해서, conv 연산이 사용된다.
low level단에서는 선, 면 등의 경계와 같은 low level 에 대한 정보, Mid level 에서는 바퀴, 등의 low level 에서 보다 경계 모습과는 달리 “물체의 모습을 을 띄는” 형태소를 가지게된다.
그리고 high level 에서는 Mid level 보다 더 feature에 대해 더 물체와 같은 모양을 띄고 있다.
다음은 컨볼루션 과정이다.
컨볼류션 연산을 모든 feature에 대해서 행하게 된다.
예를 들면 바로 위 mid level feature 사진에서 바퀴 모양의 feature 에서도 convolution 연산을 하고, 창문 모양의 feature 에 대해서도 convolution 연산을 하는 식이다.
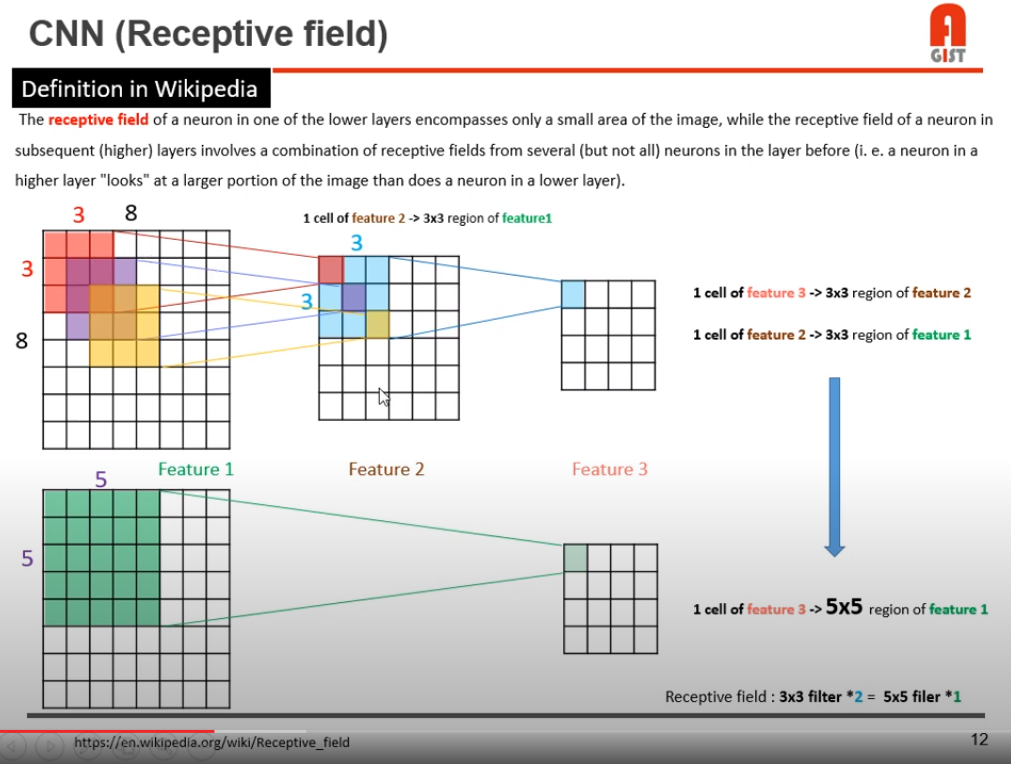
위 영상에선 모델이 깊을수록 모델의 성능이 더 잘나온다고 한다.
receptive field의 크기가 넓어지기 때문이라고 한다.
33 conv를 두 번 하는 것이 55 conv 연산을 한 번 하는 효과를 내는 것을 보면 알 수 있다.
그리고 conv 이후 activation func 부분에서 non-linear 연산을 두 번 할수있기에, complexity가 높아져서, 더 많은 추상 정보를 얻는다.(비선형성이 높아져 실제 사람이 보는 데이터와 비슷해진다고 이해했다.)
또한 33 필터 두 개는 총 18개의 파라미터를 갖으므로 , 25개의 파라미터를 갖는 55 필터보다 연산 속도면에서 우위를 갖는다.
Activation Function Part
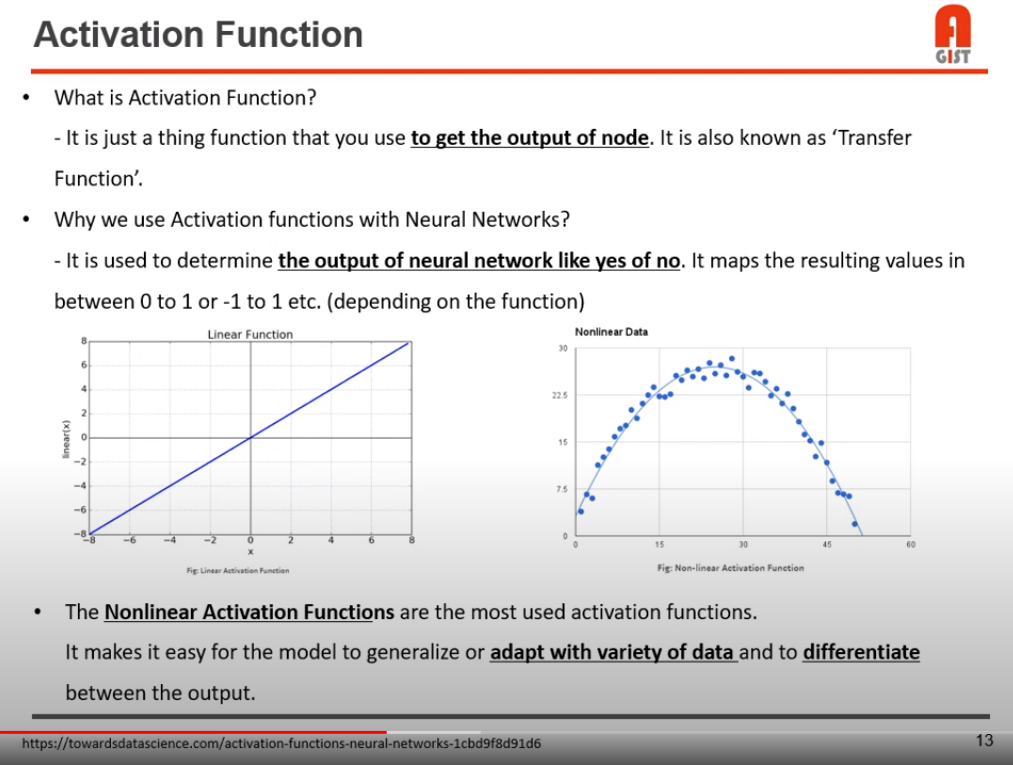

Activation function은 output으로 나오는 노드에 비선형성을 추가해준다.
보통 컨볼루션 연산을 하면 데이터들이 선형적인 값을 띄는데, activation function을 통해 비선형성을 추가해 준다.
Relu 이전 시그모이드 함수를 activation function을 쓸 때, 학습 과정에서 미분을 통해 weight를 업데이트 해주는 과정에서, activation funcion을 고치면 기울기 값이 0이 되어버려 gradient vanishing 현상이 일어난다.
학습을 아무리 돌려도 loss가 줄지 않고, accuracy 또한 일정 수준에 수렴하는 양상을 띈다.
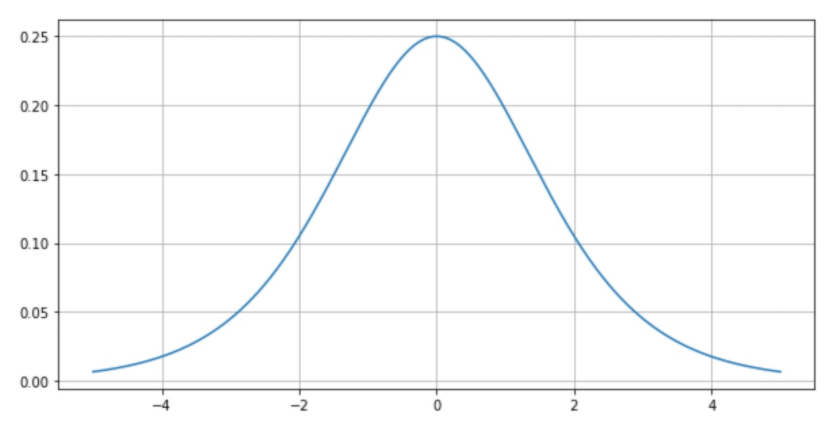
위 사진은 sigmoid 함수를 미분 한 모습이다.
기울기의 최대값이 0.25니 gradient vanishing 현상이 일어날 수 밖에 없다.
이 현상을 막기 위해 Relu function이 사용되었고, 이후 ResNet 논문에서는 Relu 를 사용했음에도 나타나는 degradtion 현상을 막기 위해 Residual 연산을 이용하였다.
Pooling Part
MaxPooling, Average Pooling 등이 있다.
Low level 에서는 Pooling이 일어나지 않았으므로 예를 들어 512512 이미지에 대해 33 conv 연산을 하는 것이므로 큰 틀의 선, 윤곽에 대해 feature map을 생성한다.
반면에 High level 에서는 Pooling이 많이 일어났을 것이고 예를 들어 55 이미지에 대해 33 연산을 하는 것이므로 작은 모양의 축구공, 병 과 같은 객체에 대해 feature map을 생성할 것이다.
Fully Connected Layer Part
Dense layer라고도 한다.
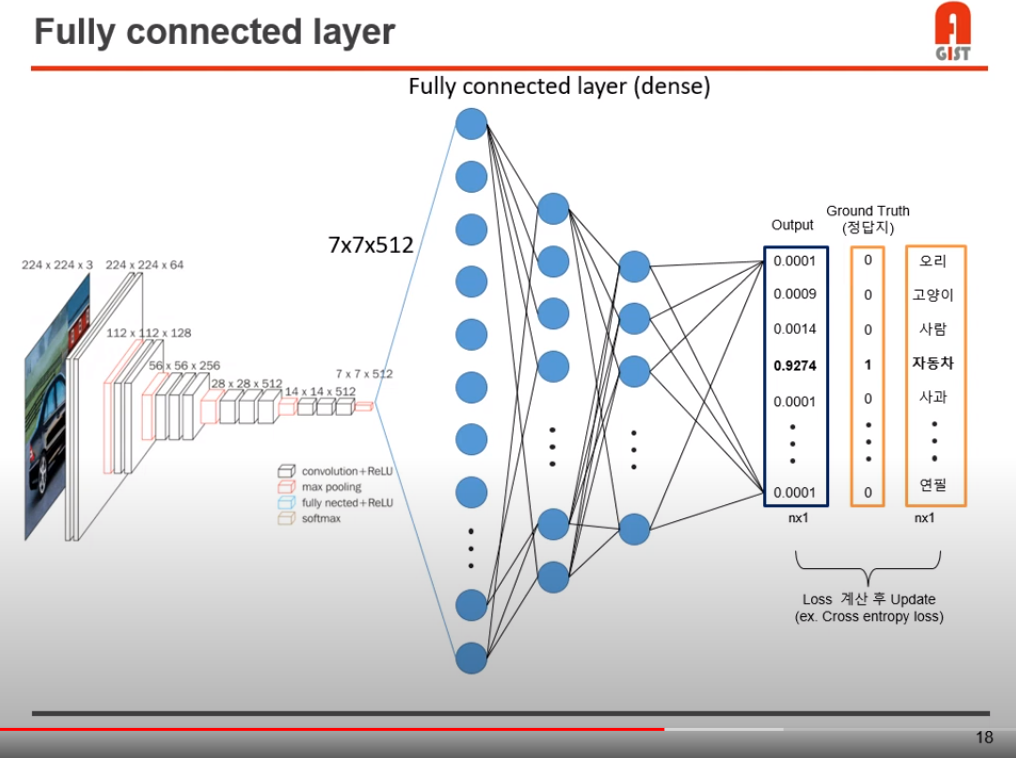
위 사진에서, FCN 입력으로 들어가는 77512 layer에 대해 모든 노드를 1열로 나열한다.
최종 output으로는, 우리가 가지고 있던 class 개수 만큼으로 출력하고, 그 class에 해당하는 확률을 출력한다.
좀 더 직관적으로 해석하자면,
출력 뉴련의 값이 성별 (남, 여)이고, 입력 뉴런이 머리카락 길이, 허리 사이즈 등 일때, 머리카락 길이 노드 의 가중치는 높고, 키 가중치 노드는 중간, 허리 사이즈 가중치노드 는 낮을 것이다.
학습 과정에서 위 가중치들이 조정된다.

위 그림은 input 노드 4개, 그리고 dense layer 3개를 거친 최종 출력 노드가 1개인 모습을 그림으로 나타낸 것이다.
Fully connected layer는 입력 뉴런의 수에 상관없이 출력 뉴런 수를 자유롭게 설정할 수 있기 때문에 출력층으로 많이 사용된다.
그리고 마지막 단에는, 모든 클래스에 해당하는 값의 합이 1이 되는 softmax 함수를 사용한다.
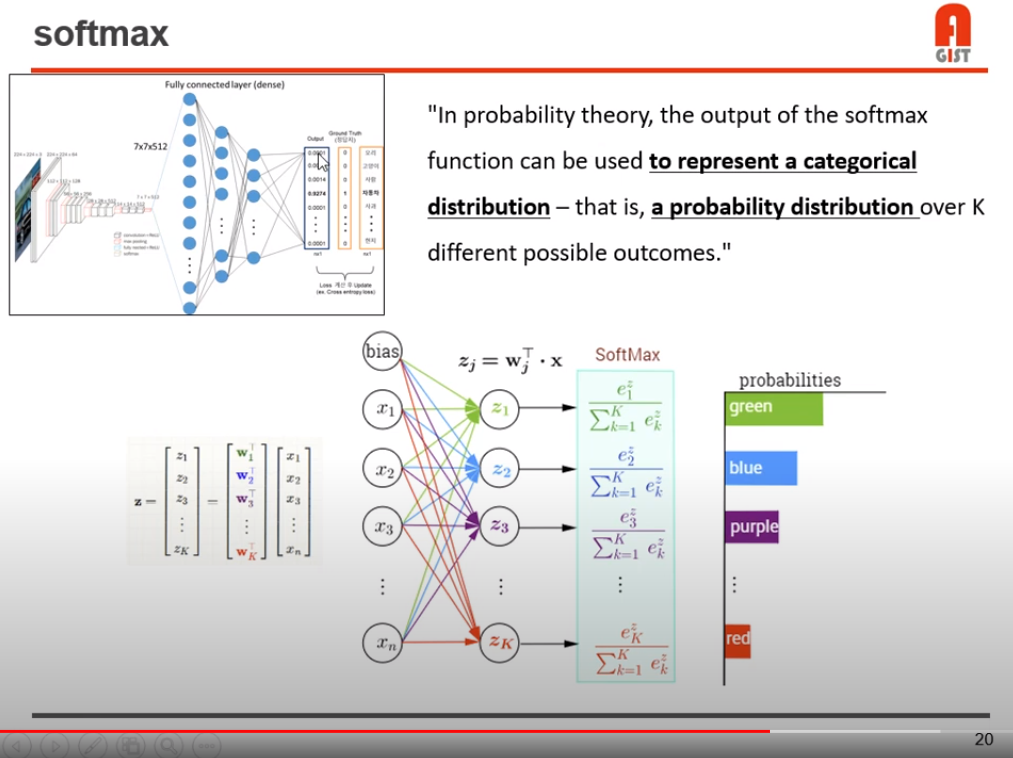
모델의 학습 과정
학습 시작부분에서, 필터의 각 weight 부분에 가우시안 분포에 따라 0~1 사이의 값을 각 픽셀마다 할당한다.
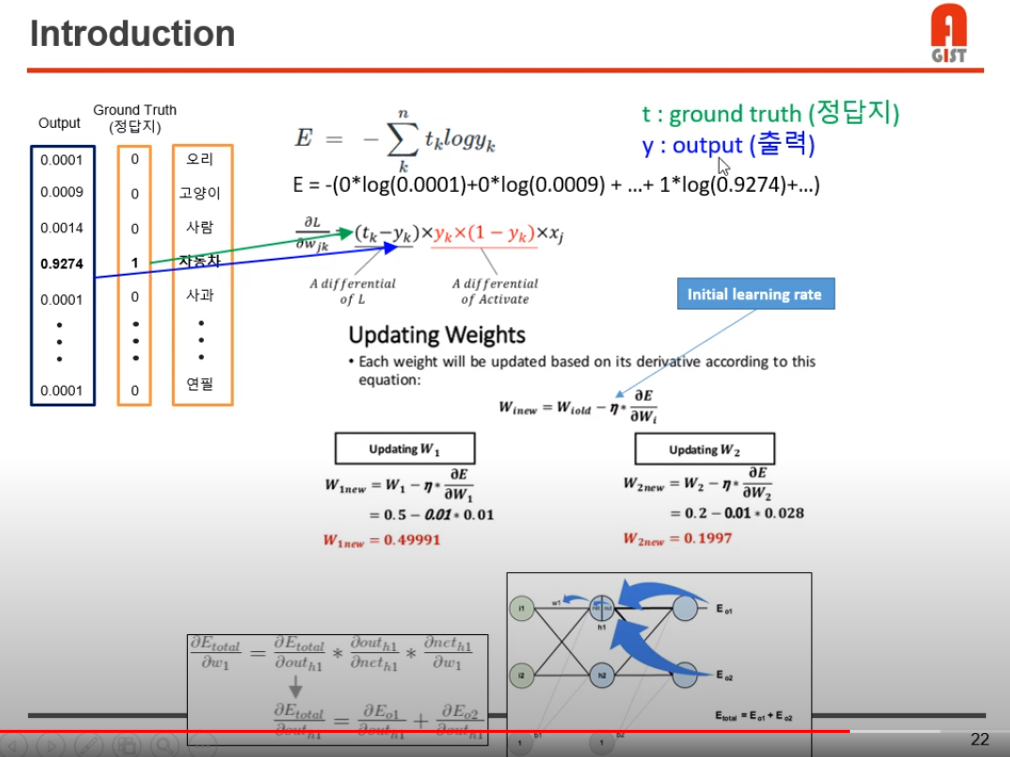
지도학습, cross entrophy 방식으로 학습 하는 환경이라 가정한다.
ground truth T에 대해, 모델이 예측하여 one hot encoding 한 yk를 input으로 하여 cross entrophy를 계속 돌리며, loss를 줄이는 방식으로 weight를 업데이트하여 모델을 학습시킨다.
Back propagation 방식이 이용된다.
https://www.youtube.com/watch?v=G0kzSRbNF6E
30:34부터 마저 듣기..
Subscribe via RSS