
VGG16 Code Implementation with Cifar-10 dataset
by
데이터셋은 여기에서 받으실 수 있습니다.
50000장의 train 이미지, 10000장의 test이미지를 받을 수 있는데, 저는 10000장의 이미지를 반으로 나누어 5000장은 Validation, 5000장은 test에 사용했습니다.
처음에는 VGG16 모델의 parameter 갯수 그대로 구현하고자 했지만, image size, class 갯수에 비해 모델이 너무 무거워, 각 레이어들을 줄이고 parameter 갯수를 약100만개로 맞추었습니다.
batch Normalization은 사용하지 않았고, dropout은 training시 사용했습니다.
CODE
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import datasets, layers, models
from keras.models import Model
from keras.layers import Flatten, Dense, Input, Conv2D, MaxPooling2D, Dropout
from keras import optimizers
cifar10 = datasets.cifar10
(train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog','frog', 'horse', 'ship', 'truck']
#valid/test dataset 나누기
valid_images = []
valid_labels = []
for i in range(5000):
valid_images.append(test_images[i])
valid_labels.append(test_labels[i])
test_images_5000 = []
test_labels_5000 = []
for i in range(5000):
test_images_5000.append(test_images[5000+i])
test_labels_5000.append(test_labels[5000+i])
test_images_5000 = np.array(test_images_5000)
test_labels_5000 = np.array(test_labels_5000)
valid_images = np.array(valid_images)
valid_labels = np.array(valid_labels)
print("Train samples:", train_images.shape, train_labels.shape)
print("Valid samples :", valid_images.shape, valid_labels.shape)
print("Test samples:", test_images_5000.shape, test_labels_5000.shape)
결과 :

#test data 잘 할당되었나 확인해보기
plt.figure(figsize=(10, 10))
for i in range(25):
plt.subplot(5, 5, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(test_images_5000[i])
plt.xlabel(class_names[test_labels_5000[i][0]])
plt.show()
#기존 VGG16에서 parameter 갯수를 줄이고, dense layer 노드 갯수를 줄였습니다.
from keras.layers import BatchNormalization
def VGG16_Brief(classes=10): # classes = 감지할 클래스 수
img_rows, img_cols = 32, 32
img_channels = 3
img_dim = (img_rows, img_cols, img_channels) #차원..shape 정의..
img_input = Input(shape=img_dim) #튜플.. 변경 x
x = Conv2D(32,(3,3),padding='same',activation = 'relu')(img_input) #1층
x = Dropout(0.256)(x)
#x = Conv2D(32,(3,3),padding='same',activation = 'relu')(x) #2층
#x = Dropout(0.15)(x)
x = MaxPooling2D((2,2),strides=(2,2))(x) #2층 maxpool
x = Conv2D(64,(3,3),padding='same',activation = 'relu')(x) #3층
x = Dropout(0.25)(x)
#x = Conv2D(64,(3,3),padding='same',activation = 'relu')(x) #4층
#x = Dropout(0.15)(x)
x = MaxPooling2D((2,2),strides=(2,2))(x) #4층 maxpool
#x = Dropout(0.25)(x)
x = Conv2D(128,(3,3),padding='same',activation = 'relu')(x) #5층
x = Dropout(0.25)(x)
#x = Conv2D(256,(3,3),padding='same',activation = 'relu')(x) #6층
# x = Dropout(0.15)(x)
#x = Conv2D(256,(3,3),padding='same',activation = 'relu')(x) #7층
#x = Dropout(0.15)(x)
x = MaxPooling2D((2,2),strides=(2,2))(x) #7층 maxpool
#x = Dropout(0.2)(x)
# x = Conv2D(512,(3,3),padding='same',activation = 'relu')(x) #8층
# x = Conv2D(512,(3,3),padding='same',activation = 'relu')(x) #9층
# x = Conv2D(512,(3,3),padding='same',activation = 'relu')(x) #10층
# x = MaxPooling2D((2,2),strides=(2,2))(x) #10층 maxpool
# x = Conv2D(512,(3,3),padding='same',activation = 'relu')(x) #11층
# x = Conv2D(512,(3,3),padding='same',activation = 'relu')(x) #12층
# x = Conv2D(512,(3,3),padding='same',activation = 'relu')(x) #13층
# x = MaxPooling2D((2,2),strides=(2,2))(x) #13층 maxpool
x = Flatten()(x)
#x = Dense(1024, activation = 'relu')(x) #14층
#x = Dropout(0.5)(x)
x = Dense(512, activation = 'relu')(x) #15층
x = Dropout(0.5)(x)
x = Dense(classes, activation = 'softmax')(x)
model = Model(inputs=img_input, output = x)
return model
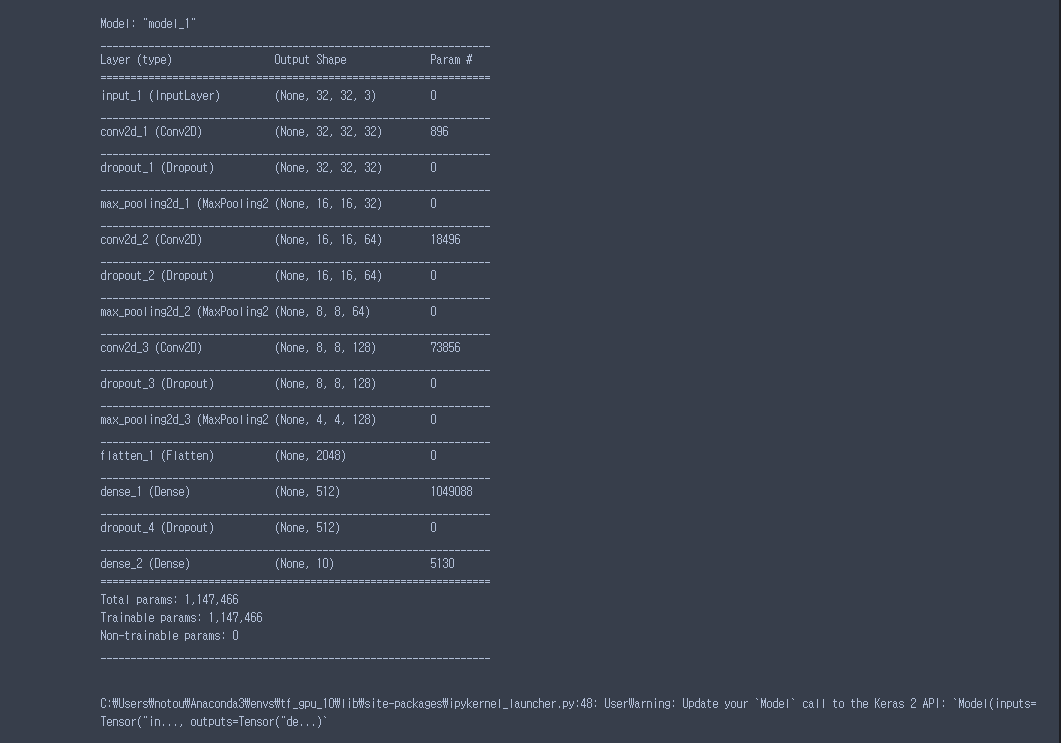
model = VGG16_Brief(classes = 10)
model.summary()
model.compile(optimizer='Adam',
loss='sparse_categorical_crossentropy', metrics=['accuracy'])
#loss를 categorical_crossentropy 대신 sparse_categorical_crossentropy 사용
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
learning_rate_reduction = ReduceLROnPlateau(monitor='val_loss',
patience=5,
verbose=1,
factor=0.1,
min_lr=0.00001)
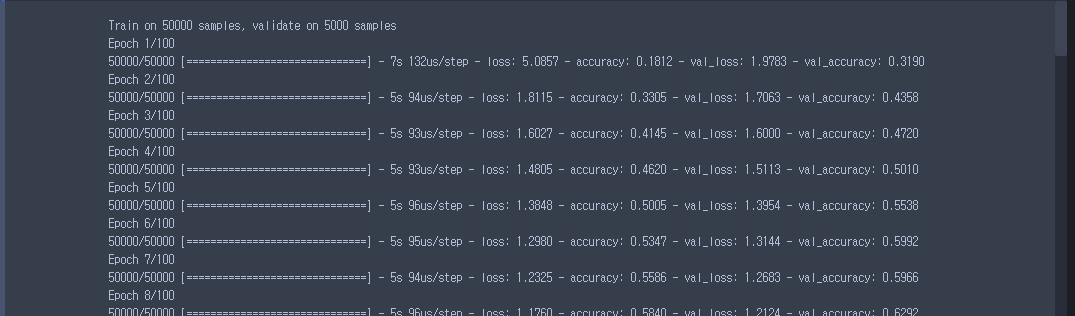
hist = model.fit(train_images, train_labels, epochs=100,
validation_data=(valid_images, valid_labels),callbacks = [learning_rate_reduction],batch_size=256)

test_loss, test_acc = model.evaluate(test_images_5000,test_labels_5000)
print('test loss:', test_loss)
print('test acc:', test_acc)

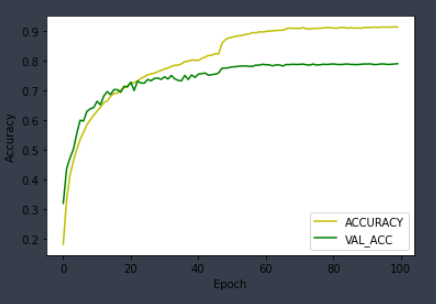
import matplotlib.pyplot as plt
plt.plot(hist.history["accuracy"], 'y', label= 'ACCURACY')
plt.plot(hist.history["val_accuracy"], 'g', label= 'VAL_ACC')
plt.ylabel("Accuracy")
plt.xlabel("Epoch")
plt.legend(loc='lower right')
plt.show()
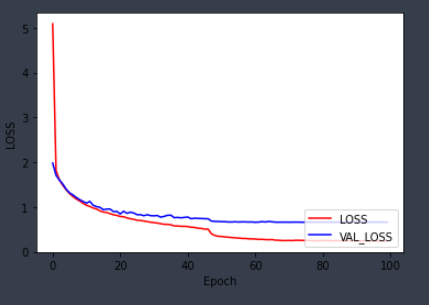
plt.subplot(111)
plt.plot(hist.history['loss'], 'r', label= 'LOSS')
plt.plot(hist.history["val_loss"], 'b', label= 'VAL_LOSS')
#plt.plot(test_acc, 'r', label= 'TEST_ACC')
plt.ylabel("LOSS")
plt.xlabel("Epoch")
plt.legend(loc='lower right')
plt.show()
감사합니다.
Subscribe via RSS