
VGG16 Code Implementation with kaggle datasets
by
데이터셋은 여기에서 받으실 수 있습니다.
총 24,000장의 사진을 사용하였습니다.
training : 강아지/고양이 각 10,000장
valid : 강아지/고양이 각 1,000장
test : 강아지/고양이 각 1,000장 을 사용하였습니다.
CODE
import numpy as np
import keras
from keras.models import Model
from keras.layers import Flatten, Dense, Input, Conv2D, MaxPooling2D
from tensorflow.keras.preprocessing.image import ImageDataGenerator #data Augmentation
def VGG16_Brief(classes=2): # classes = 감지할 클래스 수
img_rows, img_cols = 224, 224
img_channels = 3
img_dim = (img_rows, img_cols, img_channels) #차원..shape 정의..
img_input = Input(shape=img_dim) #튜플.. 변경 x
x = Conv2D(64,(3,3),padding='same',activation = 'relu')(img_input) #1층
x = Conv2D(64,(3,3),padding='same',activation = 'relu')(x) #2층
x = MaxPooling2D((2,2),strides=(2,2))(x) #2층 maxpool
x = Conv2D(128,(3,3),padding='same',activation = 'relu')(x) #3층
#x = Conv2D(128,(3,3),padding='same',activation = 'relu')(x) #4층
x = MaxPooling2D((2,2),strides=(2,2))(x) #4층 maxpool
x = Conv2D(256,(3,3),padding='same',activation = 'relu')(x) #5층
#x = Conv2D(256,(3,3),padding='same',activation = 'relu')(x) #6층
x = Conv2D(256,(3,3),padding='same',activation = 'relu')(x) #7층
x = MaxPooling2D((2,2),strides=(2,2))(x) #7층 maxpool
#x = Conv2D(512,(3,3),padding='same',activation = 'relu')(x) #8층
#x = Conv2D(512,(3,3),padding='same',activation = 'relu')(x) #9층
#x = Conv2D(512,(3,3),padding='same',activation = 'relu')(x) #10층
#x = MaxPooling2D((2,2),strides=(2,2))(x) #10층 maxpool
#x = Conv2D(512,(3,3),padding='same',activation = 'relu')(x) #11층
#x = Conv2D(512,(3,3),padding='same',activation = 'relu')(x) #12층
#x = Conv2D(512,(3,3),padding='same',activation = 'relu')(x) #13층
#x = MaxPooling2D((2,2),strides=(2,2))(x) #13층 maxpool
x = Flatten()(x)
x = Dense(256, activation = 'relu')(x) #14층
x = Dense(256, activation = 'relu')(x) #15층
x = Dense(classes, activation = 'softmax')(x)
model = Model(inputs=img_input, output = x)
return model
model.compile(optimizer=keras.optimizers.Adam(learning_rate=0.0003),
loss='categorical_crossentropy', metrics=['accuracy'])
model = VGG16_Brief(classes = 2)
model.summary()
결과 :
Model: "model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
conv2d_7 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 112, 112, 64) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 56, 56, 128) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
conv2d_10 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
max_pooling2d_6 (MaxPooling2 (None, 28, 28, 256) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 200704) 0
_________________________________________________________________
dense_4 (Dense) (None, 256) 51380480
_________________________________________________________________
dense_5 (Dense) (None, 256) 65792
_________________________________________________________________
dense_6 (Dense) (None, 2) 514
=================================================================
Total params: 52,444,610
Trainable params: 52,444,610
Non-trainable params: 0
_________________________________________________________________
C:\Users\notou\Anaconda3\envs\tf_gpu_10\lib\site-packages\ipykernel_launcher.py:35: UserWarning: Update your `Model` call to the Keras 2 API: `Model(inputs=Tensor("in..., outputs=Tensor("de...)`
데이터셋 넣기
training_dir='C://dataset//data_10000'
validation_dir='C://dataset//valid_1000_v2'
train_datagen = ImageDataGenerator(
rescale=1./255, #normalization 이미지 픽셀 값이 1/225를 곱해준다. default = 1
shear_range=0.2,#반시계 방향 밀리기
zoom_range=0.2, #줌
horizontal_flip=True #인풋을 무작위로 가로로 뒤집기
)
test_datagen = ImageDataGenerator(rescale = 1./255)
training_set = train_datagen.flow_from_directory( #폴더 형태로된 데이터 구조 바로 가저옴
#이 데이터 불러올 떄 앞에 정의한 파라미터로 전처리
training_dir,
target_size=(224,224), #폴더 내 이미지 사이즈 조정
batch_size=32, #32장씩 읽어들임
#shuffle=True,
class_mode='categorical' #2D one-hot 인코딩된 라벨 반환
)
validation_set = test_datagen.flow_from_directory(
validation_dir,
target_size = (224, 224),
batch_size=32,
class_mode = 'categorical'
)
#learnng rate 조정 필요할 시 조정해주는 code
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
learning_rate_reduction = ReduceLROnPlateau(monitor='val_accuracy',
patience=5,
verbose=1,
factor=0.1,
min_lr=0.00001)
history = model.fit_generator(training_set,
steps_per_epoch=100, #에포크 한 번 돌떄, 데이터를 몇 번 볼것인가(training데이터수/배치사이즈)
epochs = 100,
validation_data= validation_set,
callbacks=[learning_rate_reduction],
validation_steps = 100 #한 번 에포크를 돌고난 후, validation set을 통해 validation
#accuracy를 측정할 때 validation set을 몇 번 볼것인가(valdation data/batch size)
)
결과 :
Epoch 1/100
100/100 [==============================] - 63s 628ms/step - loss: 0.7020 - accuracy: 0.4925 - val_loss: 0.6920 - val_accuracy: 0.5000
Epoch 2/100
100/100 [==============================] - 57s 568ms/step - loss: 0.6926 - accuracy: 0.5166 - val_loss: 0.6875 - val_accuracy: 0.4972
Epoch 50/100
100/100 [==============================] - 47s 474ms/step - loss: 0.2040 - accuracy: 0.9197 - val_loss: 0.2866 - val_accuracy: 0.8920
Epoch 100/100
100/100 [==============================] - 45s 448ms/step - loss: 0.1782 - accuracy: 0.9284 - val_loss: 0.1737 - val_accuracy: 0.8932
성능평가
test_dir = 'C://dataset//test_1000_v2'
test_generator = test_datagen.flow_from_directory(
test_dir,
target_size=(224, 224),
batch_size=32,
class_mode='categorical')
test_loss, test_acc = model.evaluate_generator(test_generator, steps=50)
print('test loss:', test_loss)
print('test acc:', test_acc)
test accuracy 결과
Found 2000 images belonging to 2 classes.
test loss: 0.4005548357963562
test acc: 0.9087499976158142
import matplotlib.pyplot as plt
plt.plot(history.history["accuracy"], 'y', label= 'ACCURACY')
plt.plot(history.history['loss'], 'r', label= 'LOSS')
plt.plot(history.history["val_loss"], 'b', label= 'VAL_LOSS')
plt.plot(history.history["val_accuracy"], 'g', label= 'VAL_ACC')
#plt.plot(test_acc, 'r', label= 'TEST_ACC')
plt.ylabel("Accuracy")
plt.xlabel("Epoch")
plt.legend(loc='lower right')
plt.show()
plot 한 모습 :
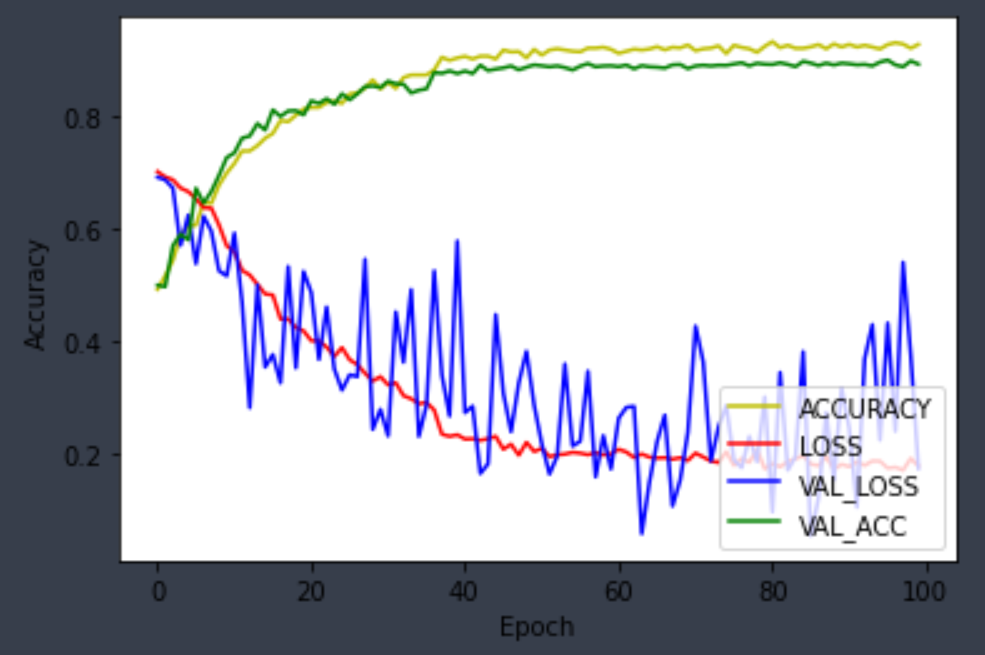
LOSS, VAL_LOSS를 비교해 보면, 40epoch 부터는 학습이 종료된 모습을 볼 수 있다.
다음에는, 클래스 개수를 늘려 CIFAR-10 dataset을 활용하여 구현에 보아야겠다.
Subscribe via RSS