
Capstone-5 DCGAN 요약 및 코드 구현
by
본 논문은 여기 에서 확인하실 수 있습니다!
여기를 참고했습니다.
about DCGAN
DCGAN은, 기존 GAN의 단점을 보완하여 더욱 성능이 높아진 네트워크입니다.
다음 네 가지 항목들을 통해, 성능을 높였습니다.
-
GAN의 구조에 대한 제약 조건들을 제안하여, 안정적으로 훈련이 진행되도록 한다.
-
Trained된 discriminator를 사용했다.
-
Intermediate 부분의 filter들을 visualize함을 통해, 특정 필터가 특정 object를 어떻게 생기게 했나를 보여주었다.
-
G 에 vector arithmetic 특성을 주어, 생성된 샘플의 sementic representation을 조작할 수 있음을 보여준다.
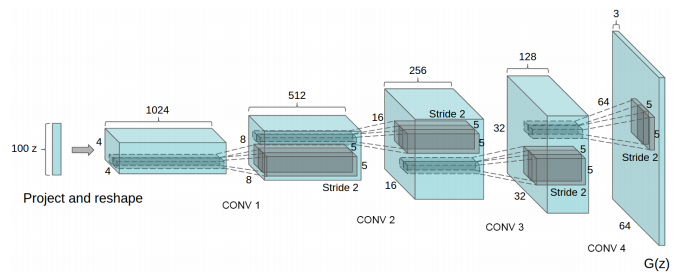
DCGAN의 구조
-
maxpooling 대신 strided convoution을 사용, FCN 대신 global average pooling 사용
-
Batch norm 사용(결과가 통일되는 model collapse 방지, initialization, gradient flow가 더 잘되도록 함)
DCGAN의 훈련 detail

Global average pooling 설명: https://gaussian37.github.io/dl-concept-global_average_pooling/
Transconvolution2D
참고한 곳 :https://wh00300.tistory.com/150
https://hyeongminlee.github.io/post/gan003_dcgan/
https://simonjisu.github.io/python/2019/10/27/convtranspose2d.html
Transconvolution2D은 conv 연산의 반대 개념이다.
자세한 개념은 위 블로그들에 기술되어 있고, 사이즈만 위주로 확인해 보겠다.

(channel , width, height)기준으로,
Conv 연산을 할 때 input이 (1024, 2, 2), padding = 2, stride = 1, kernel size = 3이면,
output은, (1024, 4, 4)이다.
이 때 위 식에 의해 p’ = (k - p - 1) = 0 이다.
s’를 1 이 아닌 2라고 했을 때, transposed Conv의 output size는 다음과 같다.
Output = (Input -1) * stride - (2 * padding) + filter + outer padding
(이 때 padding에는 p’가 들어가는게 핵심이다.)
따라서 적용해보면 5 = (2 - 1) * 2 - (2 * 0) + 3 이다.
output size는 고로 (1024, 5, 5) 이다.
참고 : ConvTranspose2d(a, b, c, d, e)라고 했을 때 각각의 인자를 설명해드리자면, a는 입력으로 들어오는 채널의 수, b는 만들어지는 결과값의 채널 수, c는 커널의 크기, 즉 Convolution 연산을 수행하는 필터의 크기, d는 stride, e는 padding
이 e(padding)은 p'로 이미 전처리 된 값이다.
CODE
import torch
import torch.nn as nn #G, D의 architecture를 정의하기 위해서 불러옴
from torchvision.datasets import MNIST
#from torchvision import datasets #Mnist dataset을 불러오기 위해
import torchvision.transforms as transforms #불러온 dataset을 전처리하기 위해
from torchvision.utils import save_image #학습이 진행되는 과정에서 반복적으로 생성된 이미지 출력 위해
latent_dim = 100
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__() #nn.module의 __init__ 사용하기 위해
self.model = nn.Sequential(
nn.ConvTranspose2d(latent_dim, 512, 4, 1, 0, bias = False),
#(in channel, out, kernel, stride, padding)
nn.BatchNorm2d(512),
nn.ReLU(),
#(512, 4, 4)
nn.ConvTranspose2d(512, 256, 4, 2, 1, bias = False),
nn.BatchNorm2d(256),
nn.ReLU(),
#(256, 8, 8)
nn.ConvTranspose2d(256, 128, 4, 2, 1, bias = False),
nn.BatchNorm2d(128),
nn.ReLU(),
#(128, 16, 16)
nn.ConvTranspose2d(128, 64, 4, 2, 1, bias = False),
nn.BatchNorm2d(64),
nn.ReLU(),
#(64, 32, 32)
nn.ConvTranspose2d(64, 3, 4, 2, 1, bias = False),
nn.Tanh(),
#(3, 64, 64)
)
#output size = (3)
def forward(self, z):
img = self.model(z) #noise z를 모델에 넣음
#img = img.view(img.size(0), 1, 28, 28) #(batch size, 채널, 높이, 너비)를 주어 이미지 형태로 만듦
return img
class Discriminator(nn.Module): #이미지를 받아 확률값으로
def __init__(self):
super(Discriminator, self).__init__()
#input channel, output chanel만 들어감. 실제 input 형태 : (3 * 64 * 64)
self.model = nn.Sequential(
nn.Conv2d(3, 64, 4, 2, 1, bias = False), # size = (3 * 64 * 64) -> (64, 32, 32)
#인자 : (in channel, out, kernel, stride, [adding, blas)
#inplace를 쓴다 -> input data 자체를 수정 -> 메모리 효율 증가 하지만 input 정보 손실
nn.LeakyReLU(0.2, inplace = True),
nn.Conv2d(64, 128, 4, 2, 1, bias = False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace = True),
#(128, 16, 16)
nn.Conv2d(128, 256, 4, 2, 1, bias = False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace = True),
#(128, 32, 32)
nn.Conv2d(256, 512, 4, 2, 1, bias = False),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace = True),
nn.Conv2d(512, 1, 4, 1, 0, bias = False),
nn.Sigmoid(),
#(512, 1, 1)
)
def forward(self, img): #한 장의 이미지가 들어왔을 떄 flatten 하여 쭉 나열하고, 모델에 넣음
# flattened = img.view(img.size(0), -1)
# output = self.model(flattened)
output= self.model(img)
result = output.view(-1, 1).squeeze(1)
return result
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1: # Conv weight init
m.weight.data.normal_(0.0, 0.02) #(평균 0.0 표준편차 0.02에서 data 뽑음)
elif classname.find('BatchNorm') != -1: # BatchNorm weight init
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
import torchvision.datasets as dsets
transform = transforms.Compose([
transforms.Scale(64),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
train_dataset = dsets.CIFAR10(root='./data/', train=True, download=True, transform=transform)
dataloader = torch.utils.data.DataLoader(train_dataset, batch_size= 128, shuffle=True)
from torch.autograd import Variable
generator = Generator()
generator.cuda()
discriminator = Discriminator()
discriminator.cuda()
loss = nn.BCELoss()
loss.cuda()
lr = 0.0002
optimizer_D =torch.optim.Adam(discriminator.parameters(), lr=lr, betas=(0.5, 0.999))
optimizer_G = torch.optim.Adam(generator.parameters(), lr=lr, betas=(0.5, 0.999))
import time
EPOCHS = 200
sample_interval = 2000
start_time = time.time()
for epoch in range(EPOCHS):
for i, (imgs, _) in enumerate(dataloader):
# 진짜(real) 이미지와 가짜(fake) 이미지에 대한 정답 레이블 생성
real = torch.cuda.FloatTensor(imgs.size(0), 1).fill_(1.0) # 진짜(real): 1
fake = torch.cuda.FloatTensor(imgs.size(0), 1).fill_(0.0) # 가짜(fake): 0
real_imgs = imgs.cuda()
""" 생성자(generator)를 학습합니다. """
optimizer_G.zero_grad()
# 랜덤 노이즈(noise) 샘플링
z = torch.normal(mean=0, std=1, size=(imgs.shape[0], latent_dim, 1, 1)).cuda()
# 이미지 생성
generated_imgs = generator(z)
# 생성자(generator)의 손실(loss) 값 계산
g_loss = loss(discriminator(generated_imgs), real)
# 생성자(generator) 업데이트
g_loss.backward()
optimizer_G.step()
""" 판별자(discriminator)를 학습합니다. """
optimizer_D.zero_grad()
# 판별자(discriminator)의 손실(loss) 값 계산
real_loss = loss(discriminator(real_imgs), real)
fake_loss = loss(discriminator(generated_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
# 판별자(discriminator) 업데이트
d_loss.backward()
optimizer_D.step()
done = epoch * len(dataloader) + i
if done % sample_interval == 0:
# 생성된 이미지 중에서 25개만 선택하여 5 X 5 격자 이미지에 출력
save_image(generated_imgs.data[:25], f"{done}.png", nrow=5, normalize=True)
print(f"[Epoch {epoch}/{EPOCHS}] [D loss : {d_loss.item(): .6f}] [G loss : {g_loss.item():.6f}] [Elapsed time: {time.time() - start_time:.2f}s]")
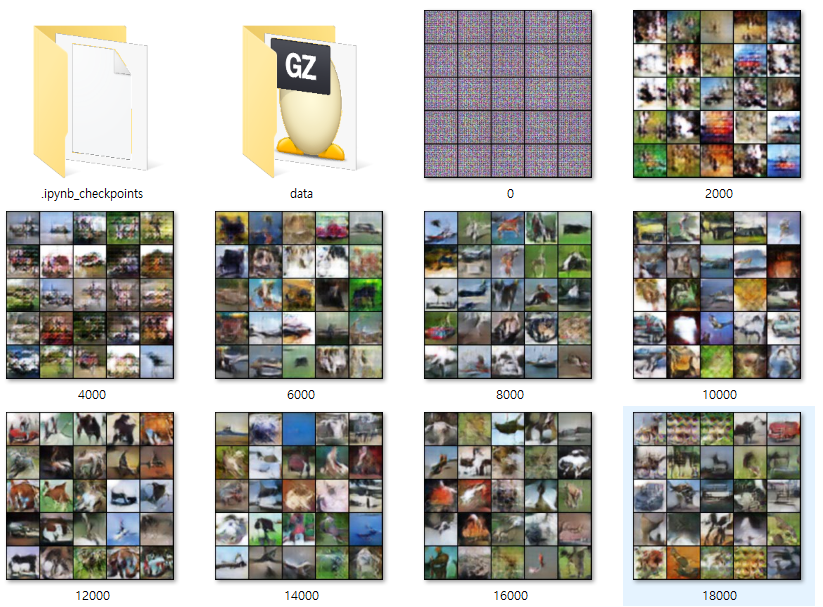
결과
50/200 에포크 (아직 학습 중)

Subscribe via RSS