
Capstone-3 PGGAN 논문 내용 요약
by
본 논문은 여기, 여기, 여기 를 참고하여 포스팅 하였습니다.
Intro
PGGAN은 17년 Nvidia에서 나온, 새로운 방법으로 고해상도 이미지를 생성하는 방법을 제안한 논문이다.
기존의 GAN은 고해상도 일수록
1) D는 G가 생성한 이미지를 너무 쉽게 구별한다.(=unhealthy competition)
2) 학습이 불안정 하다.(batch를 minibatch 단위로 쪼개어 학습시켜 이를 완화)
하는 특성을 보였다.
이를 개선하기 위해, PGGAN은 몇 가지 기법은 제안한다.
1) low resolution -> high resolution으로 갈수록 layer를 점진적으로 추가해줌
2) G와 D를 더 잘 normalize
3) generated image에 variation을 주는 기법을 추가
이에 관해 하나 하나 살펴보도록 하겠다.
Layer의 점진적 추가
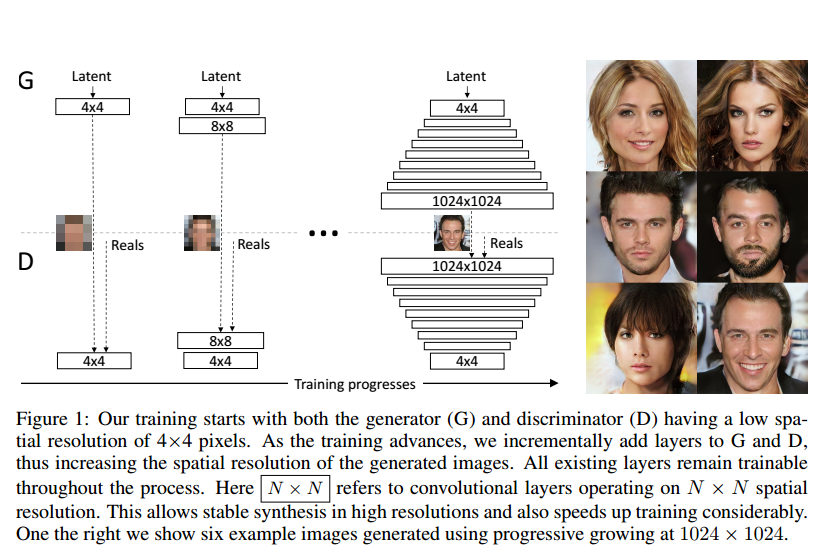
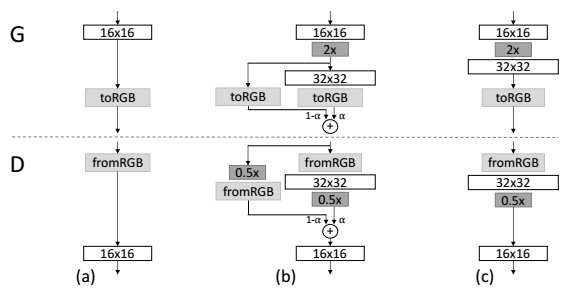
저해상도부터 시작하여 높은 해상도까지 쌓아올리는 과정이다.
a(알파 값)를 점진적으로 0에서 1로 증가시켜 (a)에서 (c)로 구조를 서서히 바꾼다.
upsampling 할 때에는 nearest neighbor interpolation을 사용하고, downsampling 할 때에는 average pooling 방식을 사용한다.
이 때 layer는 smooth한 방식으로 삽입 되는데, a를 통해 이전에 학습되어 누적되어 온 학습량과( x (1-a)), layer를 통과한 값( x a)을 더하여, 이전의 학습치들의 영향이 줄어드는 sudden shock를 방지한다.
이를 새로운 layer가 완전히 학습이 안정될 때 까지 linear하게 a가 0 ~ 1 사이 값으로 증가하도록 한다.
이 residual block 방식을 이용하면, 학습의 안정성을 높일 수 있고, 학습의 속도 또 한 빨라지는 이득을 얻을 수 있다.
이 과정에서 toRGB 는 feature vector를 RGB로 가시화 시켜주는 역할을 하며, residual block으로 사용되어야 하므로 맨 마지막 layer를 통과하기 전 부분과 마지막 layer를 통과해준 부분에 적용시켜 준다.
그리고 그 두 layer를 elementary wise하게 합한다.
fromRGB는 toRGB와 반대 역할을 하는데, RGB 를 feature vector 형태로 변환하여 D에서 확률값을 계산할 때 사용한다.
즉 이 과정을 한 문장으로 요약하자면, 처음부터 1024^2 크기의 이미지를 학습하는 것은 복잡한 task 이므로, 이를 잘게 쪼갠 low resolution -> high resolution 방식으로 이미지를 학습 하는 간단한 task로 만들어 준 것이다.
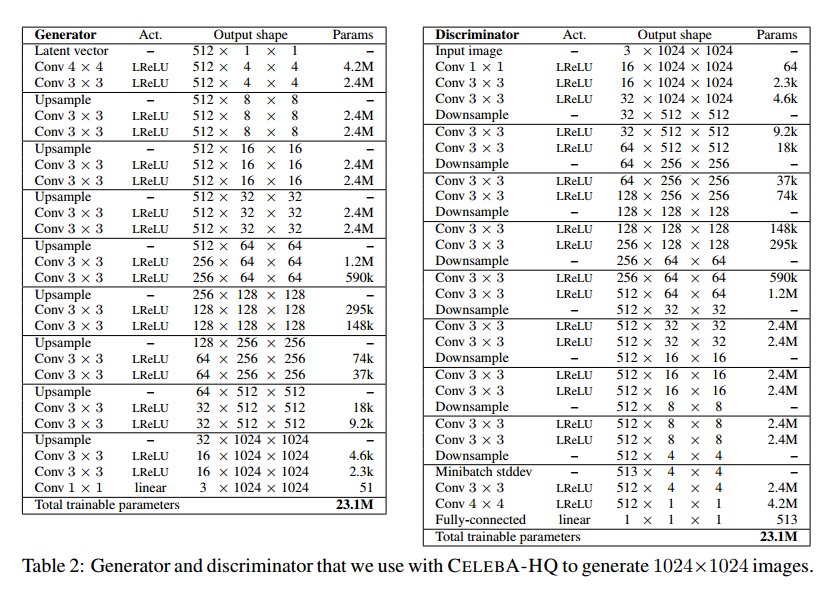
아래는 모델의 파라미터이다.
Pixelwise Normalization
본 논문에서는, Batch Normalization을 사용했지만 효과가 없었고, Pixelwise normalization이라는 기법을 사용했다.
이 기법은 픽셀 단위로 normalize해주는 기법이다.
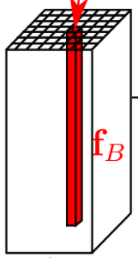
저 사진을, feature map을 위 방향으로 층층이 쌓은 모습이라고 생각해 보자.
각 한 층 한층은, 매 픽셀마다 그 층에 대한 feature을 나타내는 수치 를 나타내는 값들을 쌓아둔 것이다.
근데 이 과정에서 그 수치가 픽셀마다 너무 위로 튀는(큰) 현상이 있고 이를 normalize해주기 위해, pixel 별로 feature vector를 단위 길이(unit of length)(크기가 1)별로 normalize 해준다.
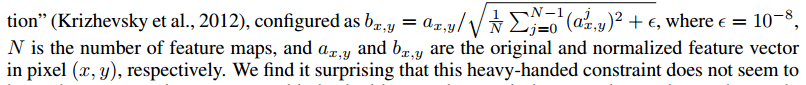
axy = original feature vector
bxy = normalized feature vector
N = feture map의 수
이를 generator의 upsampling 과정에서 각 layer의 맨 뒷단에 적용시켜 주어, 신호 크기가 제어를 벗어나는(튀는) 것을 방지해 준다.
한 feature에 해당하는 수치만 너무 크면 다른 feature에도 그 영향이 갈 것이므로 이를 픽셀 단위에서 normalize 해준다는 의미로 이해했다.
Increasing variation using minibatch standard deviation
기존의 GAN은 train data에서 찾은 feature information 보다 상대적으로 variation(변화도)가 작은 image를 생성한다.
이를 다른 표현으로 variation에 대한 subset만 학습 한다고 한다.
이로 인해 고해상도 이미지의 생성이 어려웠고, 이를 파훼하기 위해 minibatch standard deviation을 통해 해결한다.

-
먼저 minibatch(이미지를 FULL배치에서 쪼갠 것)에 대해, 각 spatial location((x, y) 좌표)에서 각 feature(feature = 한 층) 대한 표준편차를 구한다.
-
구한 spatial location의 표준 편차들을 평균내어 single value로 만든다.
-
그 값을 모든 좌표와 미니배치에 연결(concat)하여 추가적인 feature map을 산출한다.
구한 feature map을 넣어준 위치는 다음과 같은데, 이는 실험을 통해 얻은 결과라고 한다.
왜 저기에 넣었나 유추해 보자면, D의 밑으로 갈수록 더욱 구별하는 역할을 하는 위치라서 그런 것 같다.
좀 더 자유성(variation)이 높은 이미지에 대해 D가 더 확실한(맞는) 값을 낼 수 있도록하여, G가 더 variation이 높은 이미지를 생성할 수 있도록 하는 것이 원리이다.
몰랐던 표현들
feature vector들을 orthogonalize 한다 : feature vector들을 각각 기저(축)으로 하여, 다른 좌표등을 feature vecture를 중심으로 나타낼 수 있도록 한다.
Subscribe via RSS