
Capstone-2 StyleGan 논문 내용 요약
by
본 내용은 [여기]에 있습니다.





여기를 바탕으로 작성하였습니다.
Generator는 학습 데이터의 확률 밀도를 따른다 -> 설명 링크
GAN 상세설명 유재준님 -> 설명 링크
StyleGAN에서 나온 기법을 설명하는 위주로 포스팅 하겠습니다.
Intro
Style tranfer : 이미지에서 말로 하기 어려운 화가의 화풍, 그림체 등의 개념을 한 그림에서 다른 그림으로 수치화시켜 이동, 적용 시키는 개념
Generator의 각 layer에 스타일을 입힘으로써, 이미지를 생성하는 것이 styleGAN의 주 아이디어이다.
참고로 Generator의 동작 방식은, 아직 blackbox인 부분이 존재한다.
StyleGAN은 G를 제외한 D, loss부분은 건드리지 않고 GAN 구조를 사용했다.
StyleGAN의 장점
1. feature 분리 가능 :
의미를 갖는 feature(쌍커풀의 유무 등)을 명시적으로 컴퓨터에 전달하기는 쉽지 않다.
이를 컴퓨터에 전달하는 방법은 이러한 특징을 가진 이미지를 컴퓨터에 넣어주는 방법 뿐인데, 이는 상당히 고된 작업이다.
이미지 생성망이 이미지를 생성하는 근원은 random한 noise 이다(가우시안 분포에서 나온).
기존 GAN에선 머리의 색깔만 바꾸고 싶다면 어느 부분만 건드리면 되는게 아니었는데, StyleGAN에선 style을 도입하여 자연스럽게 feature가 여러 scale에서 분리, 조절 가능하도록 학습을 시켰다.
2. 부분 변화 Sampling(feature의 detail한 조절 가능케함) :
같은 사람의 얼굴이어도 다른 환경, 다른 각도에서 찍으면 여러가지 모습을 볼 수 있는데, 기존 GAN에선 하나의 이미지(한 각도에서의) 밖에 뽑을 수 없었다.
StyleGAN 에선 눈썹만, 머리색만 조절하는 등 사람의 주요 뼈대는 그대로 두고 세부적인 detail만 바꾼 sampling이 가능하다.
포스팅의 중반부에서 자세히 설명하겠다.
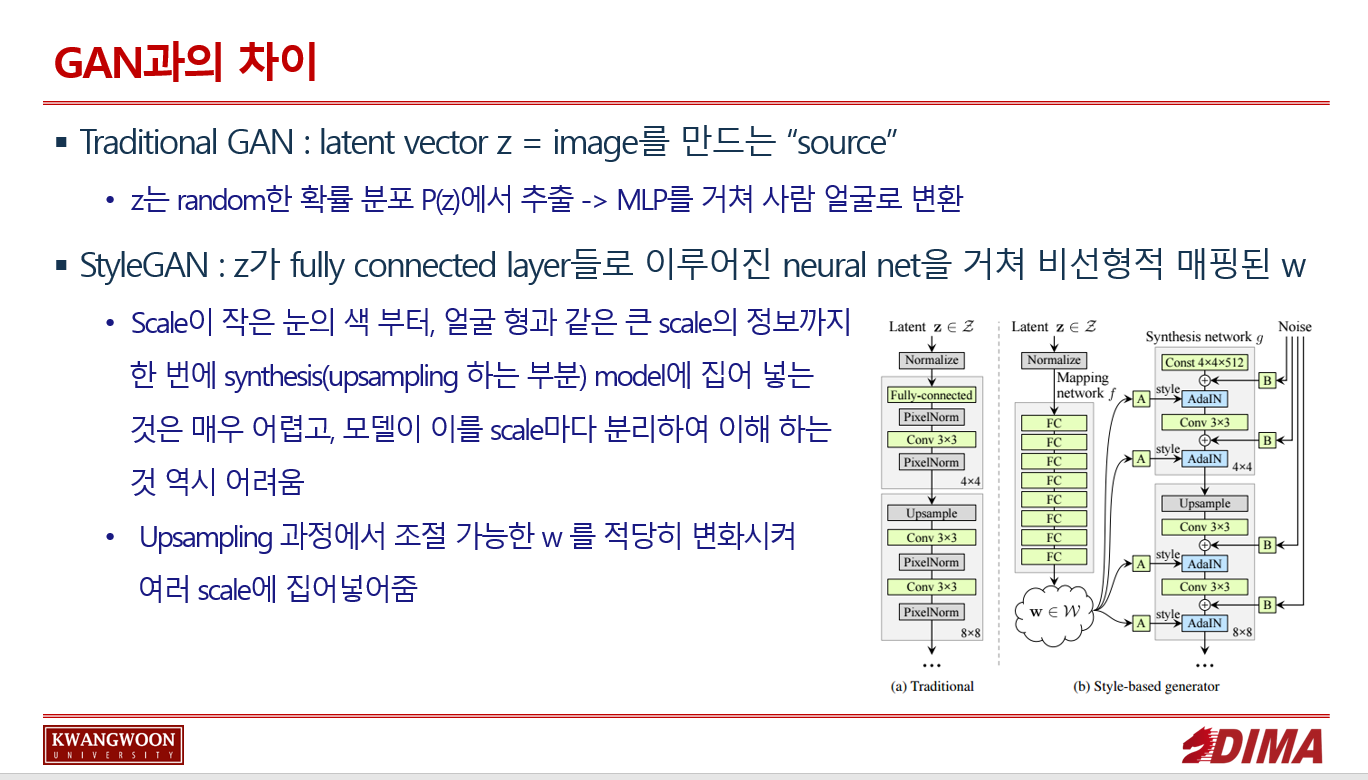
GAN과의 차이점
Generator의 구조를 제외하곤 기존의 GAN과 크게 다르지 않으므로, G의 구조만 다루겠다.
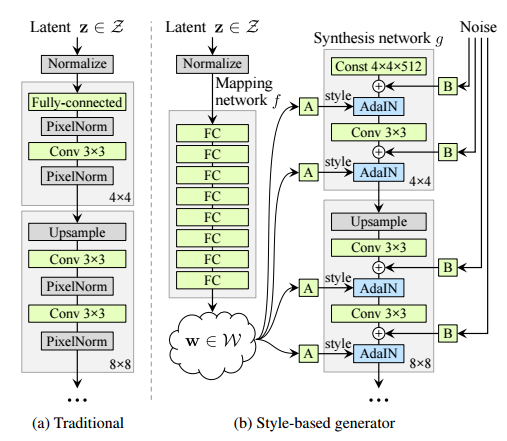
Traditional GAN : latent vector z = image를 만드는 “source”
z는 random한 확률 분포 P(z)에서 뽑아낸다.
랜덤한 확률 분포 에서 나온 z가 다중 퍼셉트론을 거쳐 p model이 학습한 사람 얼굴이 갖는 특정한 확률 분포 중 하나로 매핑된다.(?)
upsampling시 이미지가 모자이크처럼 깨져있을 것이므로 이를 다시 neural net에 넣고 돌림을 반복한다.
StyleGAN : z가 fully connected layer들로 이루어진 neural net을 거쳐 비선형적 매핑이 된 w가 되고, block으로 연결될 때 마다 upsampling 되는 방식으로 이미지를 생성한다.
scale이 작은 눈의 색 부터, 얼굴 형과 같은 큰 scale까지 한 번에 syntheses(upsampling 하는 부분) model에 집어 넣는 것은 매우 어렵고, 모델이 이를 scale마다 분리하여 이해 하는 것 역시 어렵다.
따라서, 각 upsampling 과정에서 랜덤 정도가 들어있는 w 를 적당히 변화시켜, 여러 scale에 집어넣어주자! 가 StyleGAN의 main idea 이다.
참고로 z, w는 모두 512차원 vector을 사용했다.
noise 역시 맨 처음 들어간 noise z 뿐 만 아니라, 따로 가우시안 noise들을 적당히 만들어 각 layer block에 넣어준다.
이미지가 업샘플링 될 때 마다 계속하여 style + noise를 넣어주어, 점진적으로 큰 사이즈에서 여러 style을 갖는 이미지를 만들어 낸다.
즉, w 에서 나온 정보들을 변화시켜 다른 scale마다 넣어서 세부적인 style부터 넓은 style까지 학습을 시킨다.
mapping layer는 8개의 FC layer 에서 MLP(다중 퍼셉트론)의 방식으로 시행되고, synthesis layer는 18개의 layer로 구성되어 있다.
1. Feature 분리 가능 추가 설명 : Entanglement
기존의 모델은 z가 학습 데이터의 feature 분포를 바로 맞춰야 하는 반면, styleGAN은 비선형 변환을 거친 w 가 맞추면 된다.
“feature 분리가 잘 된다” = latent space 공간 상에서 feature 들 끼리 distangled(얽혀있지 않음) 되었다라는 의미
모든 동양인들은 쌍커풀이 없다고 가정할 때, 이를 training set에 매핑한 그림은 다음과 같다.
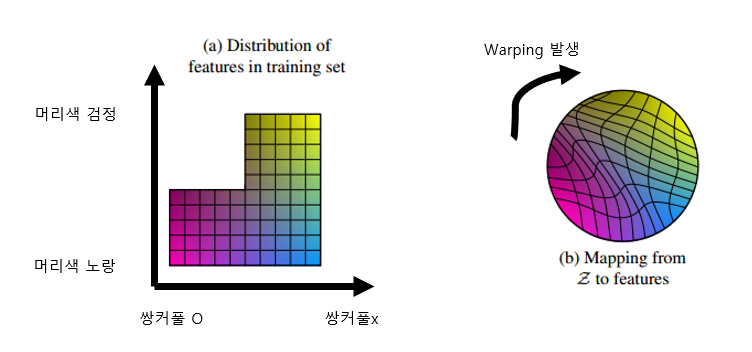
기존 GAN에선 latent space 를 원래 분포(a)를 따라가도록 학습한다.
이 과정에서 텅 빈 공간이 포함된 a로 어거지로 매핑하려다 보니, 그림b 처럼 안에서 wraping(어그러짐)이 일어난다.
이 결과 검은 선 부분을 따라가다 보면 갑자기 머리색이 비선형적으로 jump하거나, 쌍커풀이 있던 사람이 없어지는 등 매우 예측하기 힘든 결과가 나타난다.
StyleGAN은 a와 완벽히 똑같을 순 없겠지만 z -> w로의 변환을 통해 a와 비슷한 확률 분포를 가지도록 z 를 nonlinear하게 w로 wraping 한다.
이는 다음 그림과 같고 b와 비교시 어그러짐이 없음을 볼 수 있다.
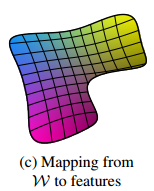
따라서 원래 공간에 있던 선형적인 구조를 더 잘 보존시킬 수 있다.
1. Feature 분리 가능 추가 설명 : AdaIN
매번 다음 스타일과 합치기 전 normalization이 이루어져, 한 스타일의 영향은 하나의 컨볼루션 연산에만 영향을 미친다
Neural net이 각 network를 거치며, scale이 변하거나(Activation의 값이 커지거나 줄음) 하는 경우가 잦다.
이 결과 학습이 불안정 해지고, batch normalization등의 방법으로 해결했었다.
본 논문은 W를 synthesis model에 넣어줄 때 normalize하는 방법을 제안했다.
AdaIN(Adaptive Instance Normalization) : w가 block에 영향(style 정보를 줌)을 끼치는 동시에 normalize까지 해준다!

CNN을 거치면서 변환된 정보가 ys,i에서 w가 가지고 있는 정보에 해당하는 만큼 곱해지고, 더해져서(yb,i) 다음 layer로 넘어간다. (w에 대한 정보가 모델에 들어가는 부분)
매 번 block마다 normalize할 때 마다, 한 번에 하나씩만 w가 기여를 하게 된다.
즉 이전 block에서의 w의 영향(머리가 곱슬거림)이 다음 block에서의 w의 영향(머리가 검정색) 되지 않도록, 다음 block으로 넘어갈 때 마다 normalize 해준다.
이 결과 한 style이 각 scale에서만 영향을 끼칠수 있도록 분리해 주는 효과를 얻었다. (= feature 분리에 좋은 영향을 끼쳤다.)
1. Feature 분리 가능 추가 설명 : Mixing regularization
서로 다른 두 z1, z2를 섞어 사용하는 것으로, 인접한 scale의 feature 사이의 correlation을 낮추어준다.
저자들이 network를 학습시킬 때, 단순히 하나의 z에서 뽑혀나온 w들에서 학습시킨 것이 아니라, 하나는 z1에서 뽑고(->w1) 하나는 z2에서 뽑아 (->z2) 각기 다른 scale에 넣어 혼합하여 학습(예를 들어 w1은 4^2 ~ 16^2, w2는 이어서 16^2 ~ 64^2) 시키는 mixing regularization을 도입했다.
이 이휴는, latent z공간의 변수들은 서로 독립일 수 있어도, w공간에서 나온 변수들은 독립이 아닐 수 있다. (잘 이해 x)
ex) 머리가 감은 사람은 항상 쌍카풀이 있게 될 수 있다.(하나의 z에서 나온 하나의 w로만 학습하기에, feature 사이 correlation이 생기는 overfitting이 발생할 수 있다.)
다시 말해 윗 block과 아래의 block사이에 correlation이 생길 수 있다.
이를 방지하기 위해 w1과 w2를 반 씩 섞어 학습하여, feature들끼리 더 잘 분리가 될 수 있게 하였다.
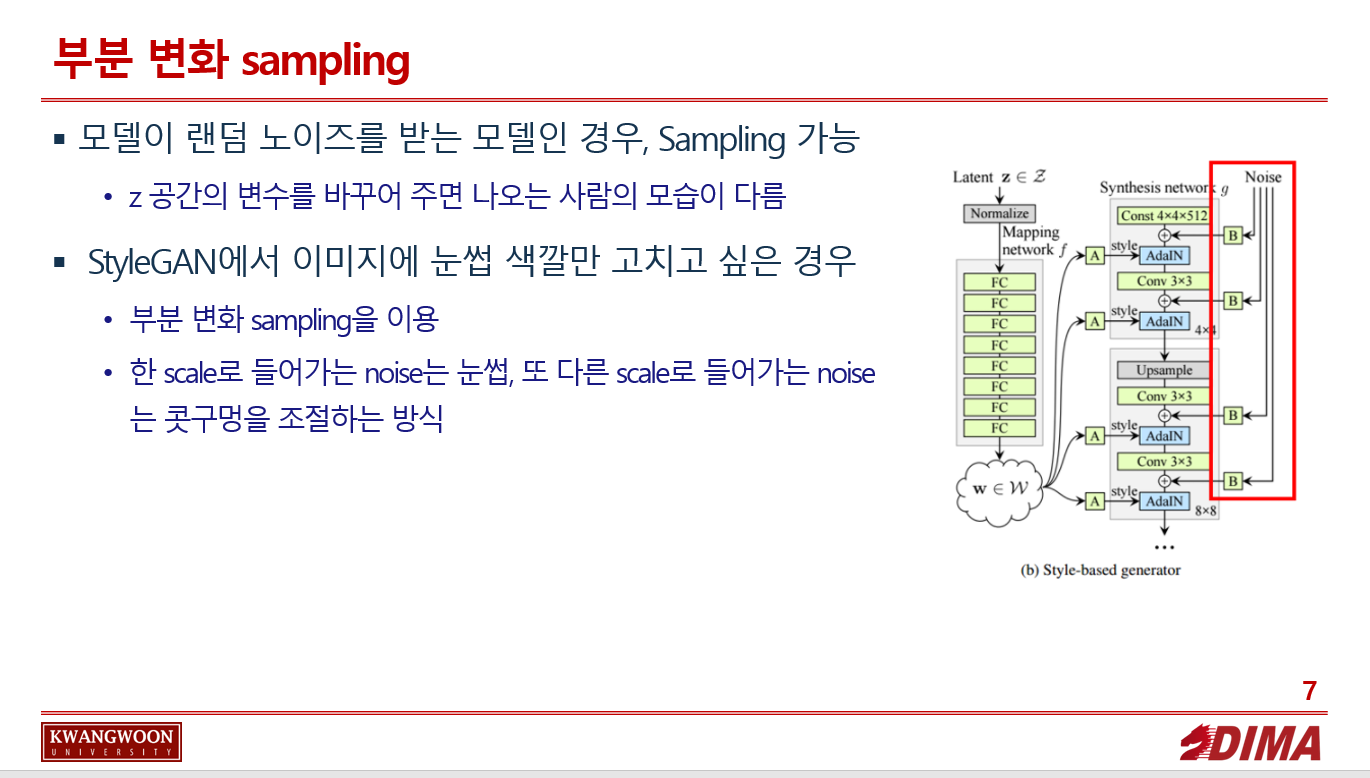
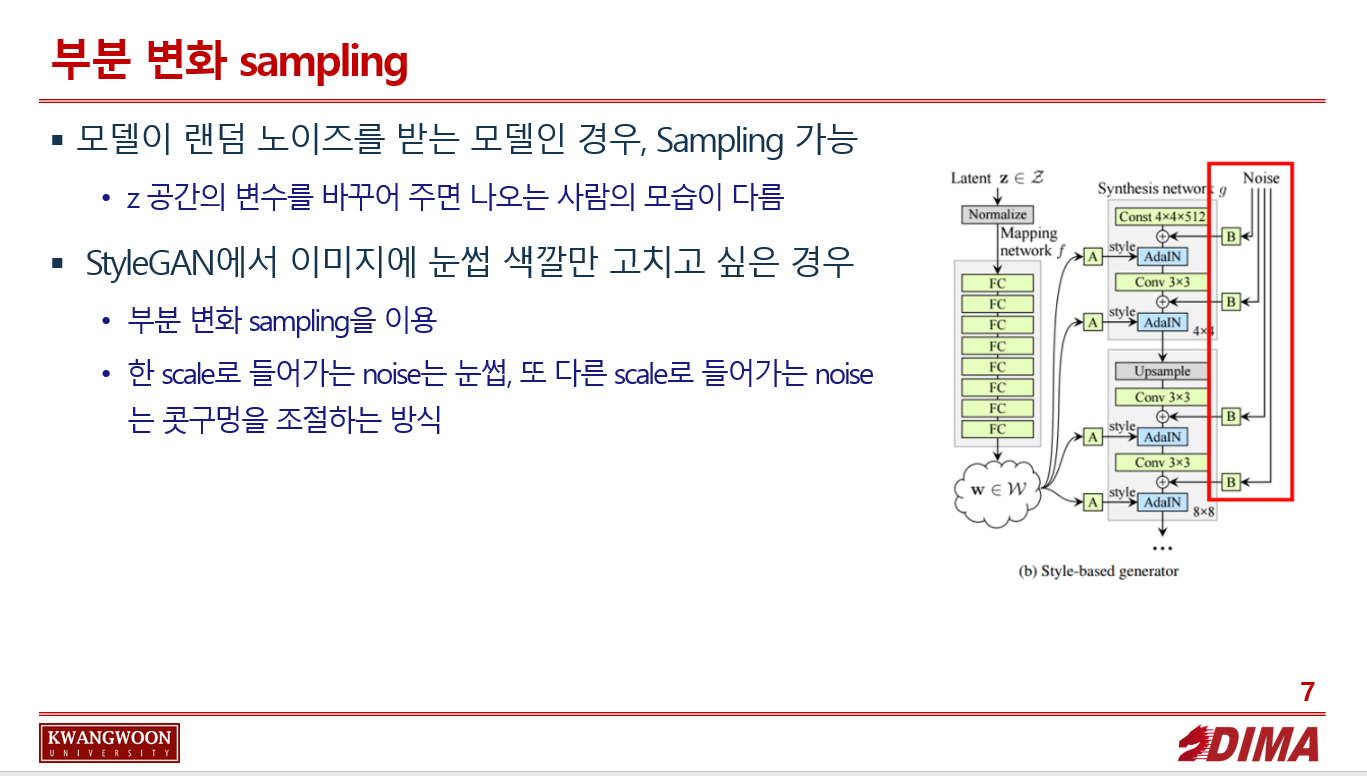
2. 부분 변화 Sampling 추가 설명
모델이 랜덤 노이즈를 받는 모델인 경우, Sampling이 가능하다.(=z공간의 변수를 바꾸어 주면 나오는 사람의 모습이 다르다.)
이 때 이미지에 눈썹 색깔만 고치고 싶은 경우? -> 부분 변화 sampling을 이용한다.
StyleGAN의 경우 각기 다른 scale마다 noise를 뿌려서 넣어주고 있다.
기존의 신경망의 경우 neural net이 이미지를 만들어 낼 때 눈 썹에 대해서도 조절하고 싶고 콧구멍 크기에 대해서도 조절하고 싶을 때, 눈썹에 대해 잘 분석하여 random성을 뽑아내서 콧구멍 크기에 대입하는 수 밖에 없었다.
StyleGAN에서는 각 scale에 noise를 각각 집어넣어 주면, 위 분석 과정이 필요 없어 진다.
한 scale로 들어가는 noise는 눈썹, 또 다른 scale로 들어가는 noise는 콧구멍을 조절하는 식이다.
다음 박스친 부분이, 각기 다른 scale에 noise를 넣어주는 모습이다.
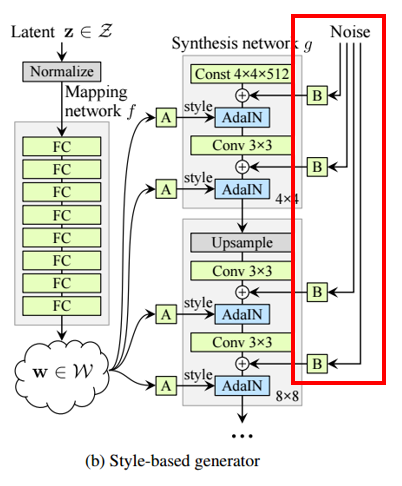
근데 특정 noise를 눈썹을 조절하는 noise로 할당하는 방식은 아니고 랜덤하게 정해지는 것 같다..?
Perceptual path length
StyleGAN팀이 제안한 새로운 성능 평가 지표 이다.
기존 feature 분리 정도를 수치화 하고 싶은 때엔, z의 variable의 한 차원만 1~20까지 변하도록 만든 20장에 대해 실험자들에게 “무슨 틀징을 변화시켜가며 생성한 이미지 같은가?”라는 질문을 통해 점수를 산정했다.
이 방법 대신, 이미지를 잘 분류하도록 학습된 신경망 VGG의 conv layer의 중간 부근에서(VGG16의 경우 8번째 conv layer, 이 구간의 feature들은 이미지에 대한 feature를 잘 가지고 있다), 두 이미지 간 얼마나 틀린지를 인지적 거리로 삼으면 어떨까? 라는 idea에서 나온 것이 perceptual path length 이다.
위 idea를 적용한 결과 결과는 더 좋았지만 왜 그런지 설명은 불가능(unreasonably good)했다.
실제 사람이 생가하는 인지적 거리와 비슷하다는 결과 또한 얻었다.
이를 styleGAN에서 z, w에 대해 비교해 봤는데, w공간에서 test 했을 시, z 에서 했을 때 보다 perceptual path length가 더 적음(성능 굿)을 확인 할 수 있었다.
*perceptual path length는 feature 간 분리가 더 작을 수록 낮은 수치를 나타낸다.)
Subscribe via RSS