
Batch Normalization
by
Gradient Vanishing
Layer를 거쳐 나갈수록, 입력단에 가까운 파라미터 값(기울기 값)이 output에 그다지 영향을 미치지 못하는 현상이다.
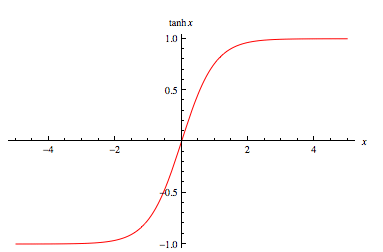
이는 sigmoid, tanh등 입력을 (0~1)사이의 값으로 매핑시켜주기에 일어나는 현상인데, Relu함수를 통해 양수 입력 값은 그대로, 음수 입력 값은 0으로 매핑시켜 gradient vanishing현상을 어느정도 줄일 수 있었다.
Relu의 사용은 회피책은 될 수 있지만, 해결책은 될 수 없었다.
2015년 Resnet에서 제안된 Residual learning과, Batch normalization으로, layer가 깊어져도 학습이 더 잘되도록 하는 방법들이 제안되었다.
Internal Covariate shift
네트워크의 각 층이나, activation function마다 input의 distribution이 달라지는 현상이다.
즉 학습하는 도중 이전 layer의 parameter의 변화로 현재 layer의 입력 분포가 바뀌게 되는 개념이다.
각 layer들의 input distribution이 consistent하지 않음을 의미한다.
Whitening
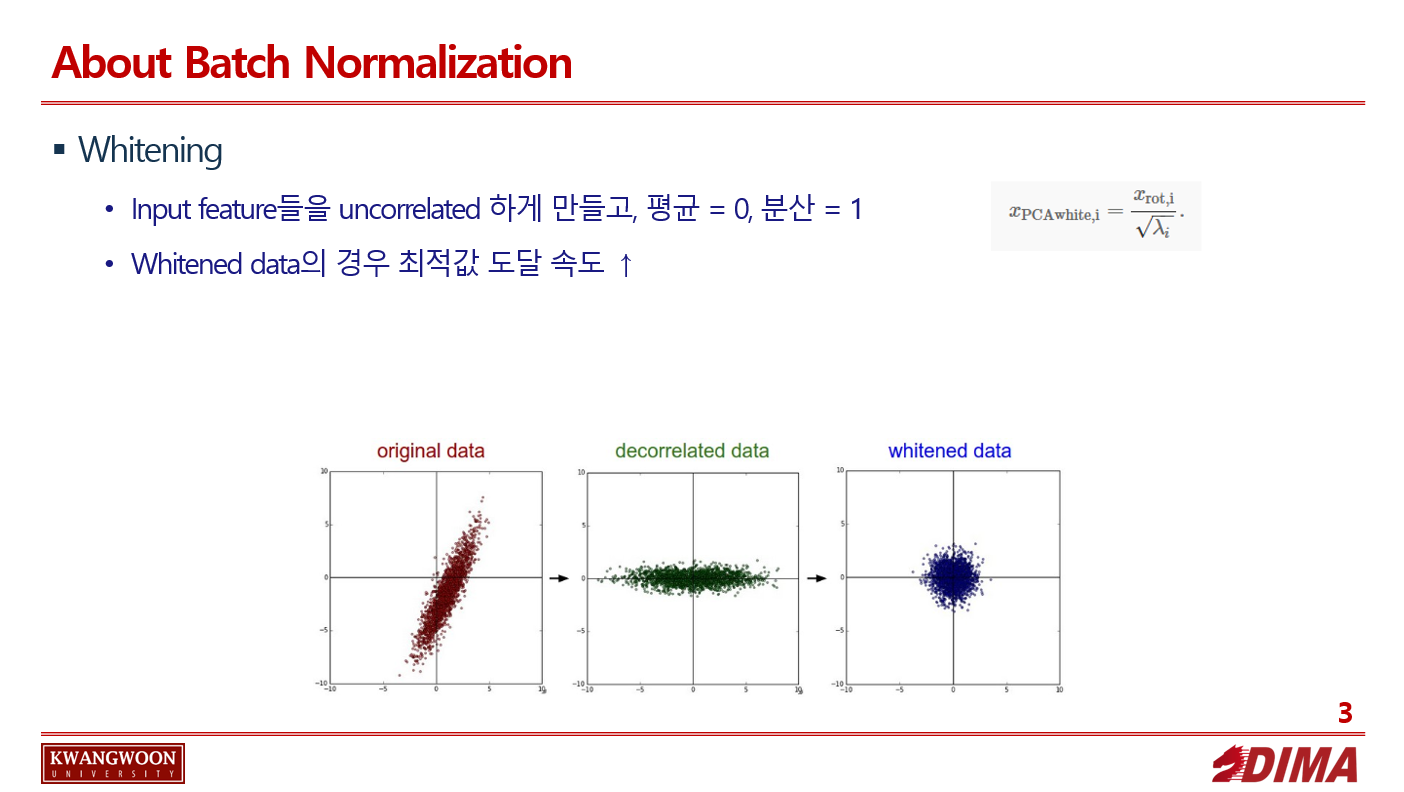
입력 데이터들의 분포가 치우쳐짐을 막고자, 데이터의 특성에 맞게 각 층의 input의 distribution의 평균을 0, 표준 편차를 1로 normalize 시켜준다.
이에 따라 input의 feature들을 어느정도 uncorrelate하게 만들어주고 각각의 variance를 1로 만들어준다.
하지만 이 방법 역시 이전 레이어로부터 학습이 가능한 parameter들의 영향을 무시하기에 제대로된 학습이 이루어지지 않는다.
Batch normalization
2015년 발표 이후 대부분의 딥러닝 부분에서 적용되는 기법이다.
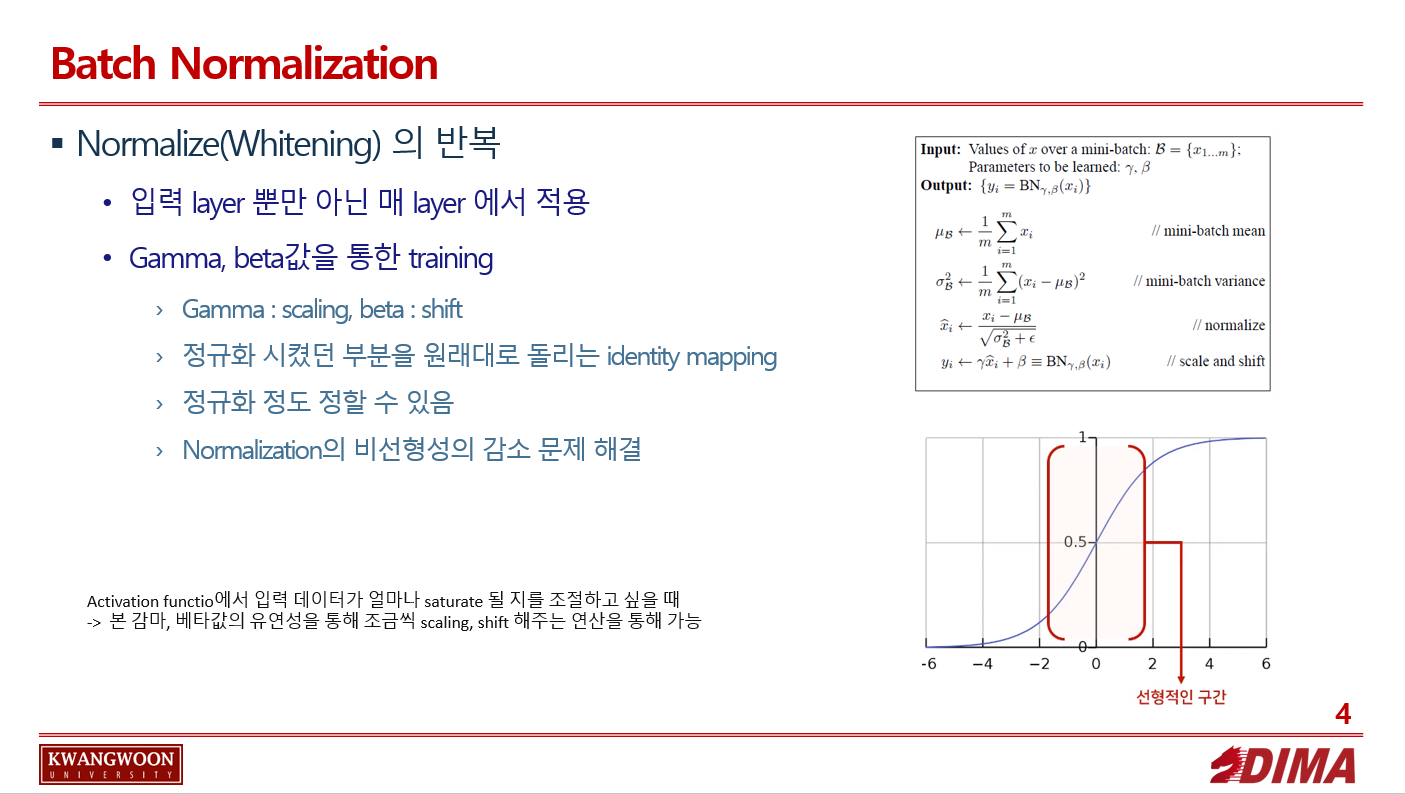
입력 layer 뿐만 아닌 각 layer 마다 normalize를 취해주면 어떨까? 라는 아이디어에 기인한 기법이다.
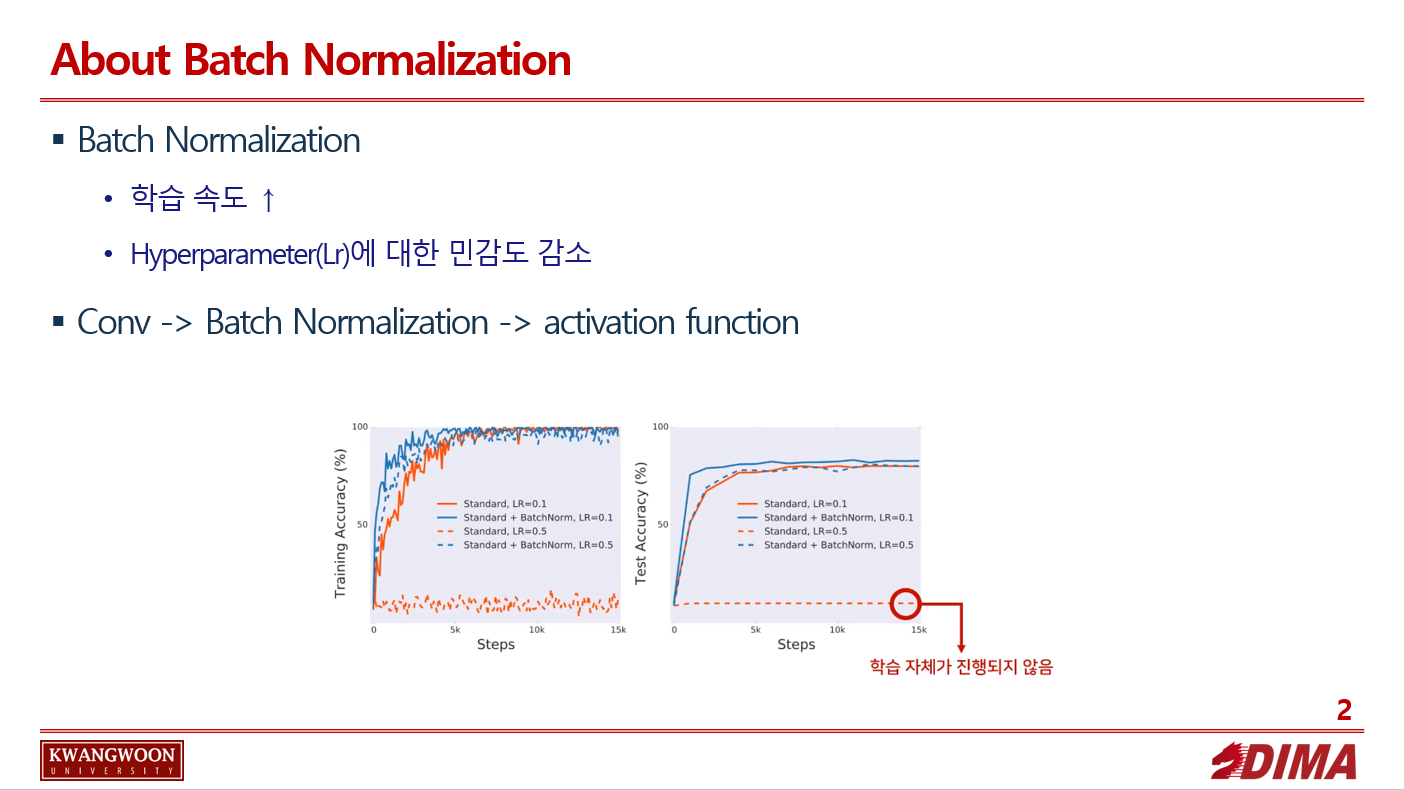
이를 통해 학습속도, hyperpamater어 대해 강건한 모습을 보인다.
주 목적은 앞서 말한 Internal Covariate shift 현상을 없애는 것이다.
Internal Covariate shift에 대해 좀 더 자세히 설명하면, 입력 데이터가 각 축에 대해서 정규분포를 띈다 하더라도, layer가 정규분포를 거쳐가면서 각각 hidden layer 입력으로 들어가면 분포가 뒤틀린 모습으로 바뀔 수 있다는 개념이다.
Batch normalization을 취한 방법은 아래와 같다.

-
batch 단위로 한 레이어에 입력으로 들어오는 모든 값들을 각각에 대해 scalar 형태로 평균, 분산을 구하고 각각 normalize한다.
-
normalized 된 값들에 cale factor (gamma)와 shift factor (beta)를 더해주고 이 변수들을 back-prop 과정에서 같이 train 해준다.
1의 과정은 일반적인 whitening을 매 layer마다 적용하는 방식이다.
2는, scale과 shift 연산을 위해 추가되었고, 이 parameter들을 통해 정규화 시켰던 부분을 원래대로 돌리는 identity mapping또한 가능해진다.(감마 : 스케일링, 베타 : 이동)
이를 통해 네트워크가 데이터를 activation function에 얼마나 saturation 시킬지를 학습할 수 있기때문에, 이를 조절할 수 있는 유연성을 얻을 수 있다.
다시 말해 Batch norm이 하는 일은 layer를 정규 분포를 만드는 일이지만, 이렇게 normalize 된다는게 항상 좋은것은 아니다.
activation function에서 입력 데이터가 얼마나 saturate 될 지를 조절하고 싶은 데, 본 감마, 베타값의 유연성을 통해 조금씩 scaling, shift 해주는 연산을 통해 학습의 유연성을 제공해 준다.
Batch normalization의 test 시의 사용
학습 시에는 mini batch 단위에서 평균과 분산을 구했지만, test 시에는 위에서 구한 값을 사용하지 않는다.
Test 시에는 minibatch, stdev가 존재하지 않으므로, 전체 training data에 대해 mean, stdev를 계산하여 batch norm을 한다.(여러개의 미니배치로 나누어 위 mean, stdev를 평균냄)
감마, 베타 역시 학습시 구한 미니배치마다의 감마, 베타값을 평균낸 값을 사용한다.
Batch normalization 2018
2018년 제안된 논문에 따르면, Batch norm은 ICS 를 낮추기위해 제안되었지만, 실제로 ICS를 낮추진 않았고 weight에 따른 loss를 smooth 해주는 특징에 의해 좋은 결과가 나왔다고 말하고 있다.


Subscribe via RSS