
GCANet_발표자료
by
발표자료

발표 시작하겠습니다.
저는 광운대학교 전자공학과 학부생 김동균입니다. 저는 Gated Context Aggregation Network for Image Dehazing and Deraining이라는 논문을 리뷰했습니다.
이 논문은 2018년 발표되었는데요, 발표 당시 사진에 껴있는 안개나 비 등을 제거하는데 가장 앞섰던 논문이고, 저는 이 논문에서 제안된 한 가지 기법에 중점을 두어 발표하겠습니다.


대기 중 안개나 먼지등 미세한 입자로 인해 이미지의 채도나 대비등이 손실되는 현상을 Hazing이라 합니다.
Haze가 추가된 이미지로부터 원본 이미지를 복원해 주는 논문은 꾸준히 나왔고 저는 이 중 2018년 당시 가장 복원율이 높았던 (Gated Context Aggration Network for Image Dehazing And Deraing) 논문을 리뷰했습니다.
Haze를 제거하는 이미지 Dehazing 작업은 딥러닝 의 발전 전후로 나뉩니다.
딥러닝의 발전 전에는, 대부분의 기술은 아래 식을 보시면 알 수 있듯이 대기 투과율과, 자연광을 예측하는 방식으로 이루어졌습니다.
이 식을 간단히 해석해 보면, 대상으로부터 반사된 신호 J(x)는 대기 투과율 t(x)와 곱해져 J(x)t(x)가 되고, 주변 광원에서 나온 A와 섞여 I(x)가 관측자에게 도달됩니다.
클린한 이미지인 J(x)를 복원하기 위하여 대기투과율(t(x))과 자연광(A)을 예측해야 했는데, 이는 매우 어려운 문제라서 복원 이미지인 J(x)는 실제 이미지와 같아지는게 쉽지 않았습니다.
딥러닝의 발전 이후, 더 이상 위의 식을 이용하여 대기투과율과 자연광을 예측하지 않고, end to end 방식의 대용량의 training set을 이용하여 neural net 을 학습시켜 이미지 복원을 하는 기법이 연구되었습니다.
본 논문은 end to end 방식의 딥러닝 기법에 Smoothed dilated convolution 기법을 더하여 복원율을 높였습니다.
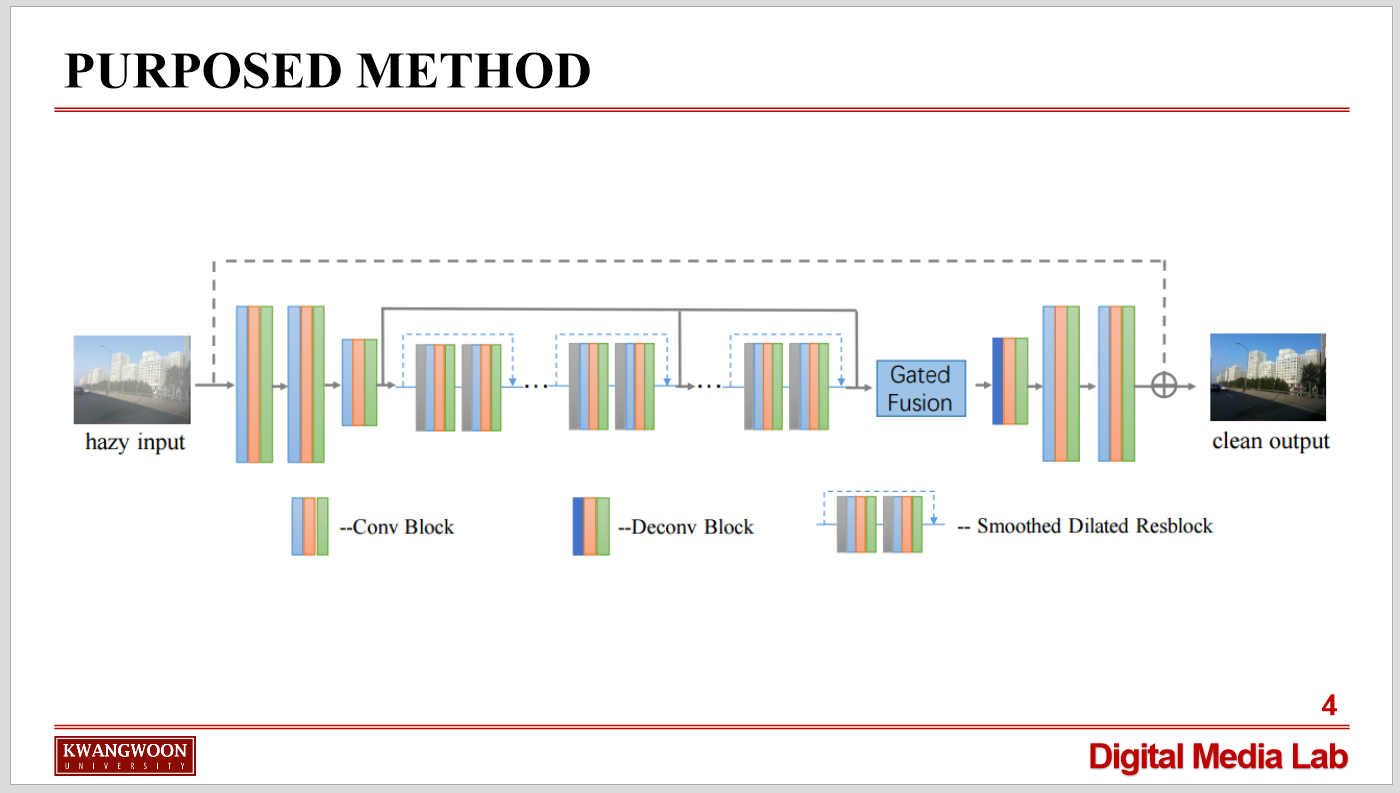
딥러닝 기반의 이미지 haze 제거를 살펴보면, 딥러닝은 Neural Net과 저장된 network weight를 활용하는 방식으로 이루어집니다.
수 천장의 haze가 추가된 사진을 input으로 주고, haze에 의해 왜곡되기 전인 클린한 이미지를 output으로 주어, haze만을 추출하는 Neural Net을 학습시킵니다.
그리고 그 과정에서 가중치인 weight를 저장합니다. 학습이 끝난 후 실제 이미지에 대해 dehazing을 할 때에는 위 과정에서 학습된 weight를 활용하여 haze가 제거된 클린한 이미지로 복원을 합니다.
위의 과정을 토대로 많은 딥러닝 기반의 dehazing 기반의 논문들이 나왔고, 본 논문 역시 위 방식에 두 가지 기술을 더해 복원율을 높였습니다.
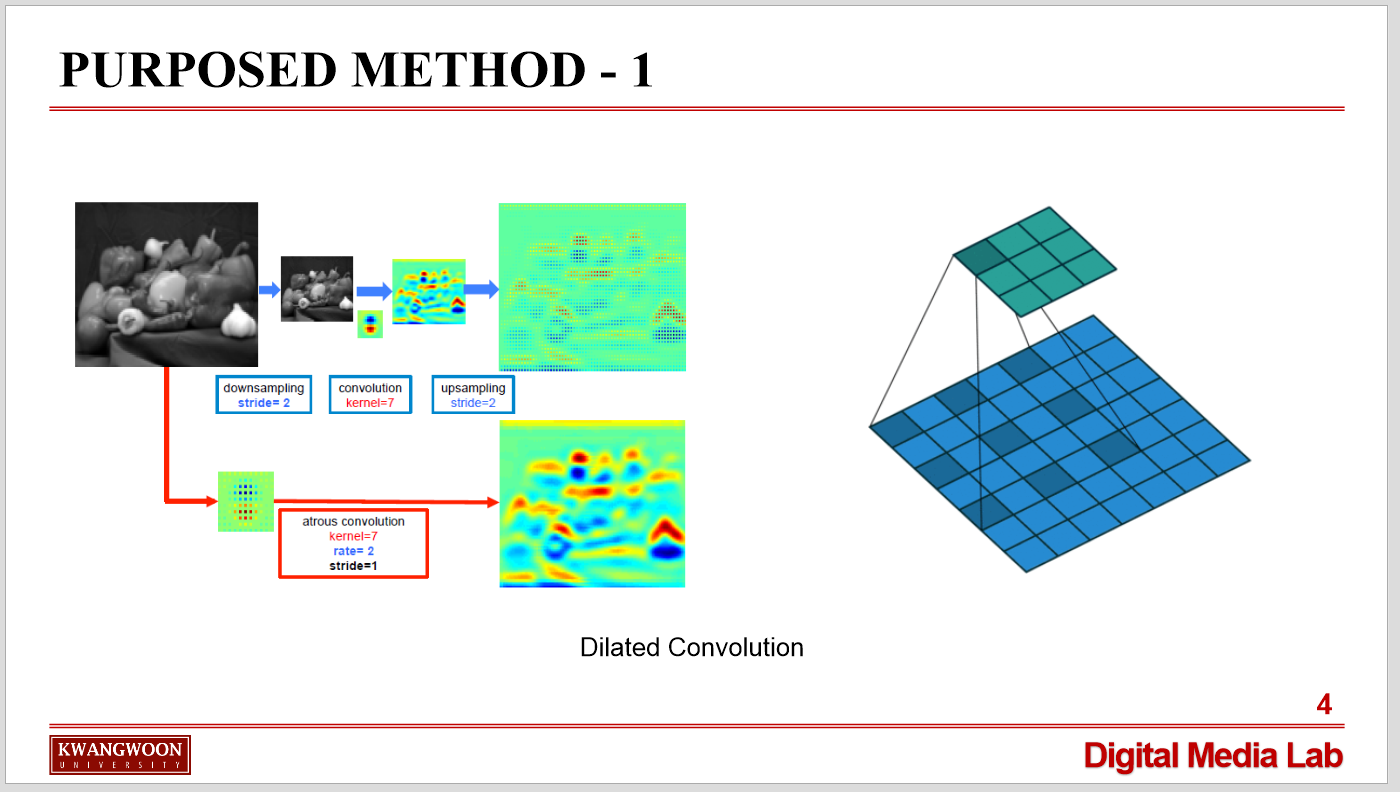
첫 번째 기술인 smoothed dilated convolution입니다.
이 기술은, dilated convolution의 결점을 완화시킨 기술입니다. 먼저 dilated convolution이란 다운샘플링과, 컨볼루션 그리고 업샘플링을 반복하는 뉴럴넷 모델에서 발생하는 해상도 손실을 줄여주는 기술입니다.
컨볼루션 레이어를 통해 이미지의 전체적인 특징을 잡아내기 위해서는, receptive field가 클수록 좋은데, receptive field가 커지려면 filter size가 커져야 하고 이는 연산량 증가를 의미합니다. 따라서 receptive field 면적을 넓히기 위해 이미지를 다운샘플링 후, 컨볼루션을 하고 다시 업샘플링을 하는데 이 과정에서 해상도 저하가 일어납니다.
해상도 저하를 막기 위해, receptive field의 사이즈를 키워주고 그 늘어난 만큼의 사이 공간을 zero padding 한 후 위와 같이 컨볼루션 해주면, 다운샘플링과 업샘플링 과정이 없어도 되고 해상도 저하또한 없어지게 됩니다.
그런데 이 dilated convolution의 단점은, output 에이어에서 각 픽셀은 바로 옆 픽셀과 receptive field 정보가 전혀 다릅니다.
이를 gridding artifact라 부릅니다.
zero padding을 한 후 한 칸씩 간격을 두어 컨볼루션했기 떄문인데, 이 gridding artifact 현상을 막기 위해 smoothed dilated convolution는 컨볼루션 이전 층에 커널 사이즈 (2r – 1)의 extra convolutional layer를 추가해 줍니다. 여기서 r은 dilation rate를 의미합니다.
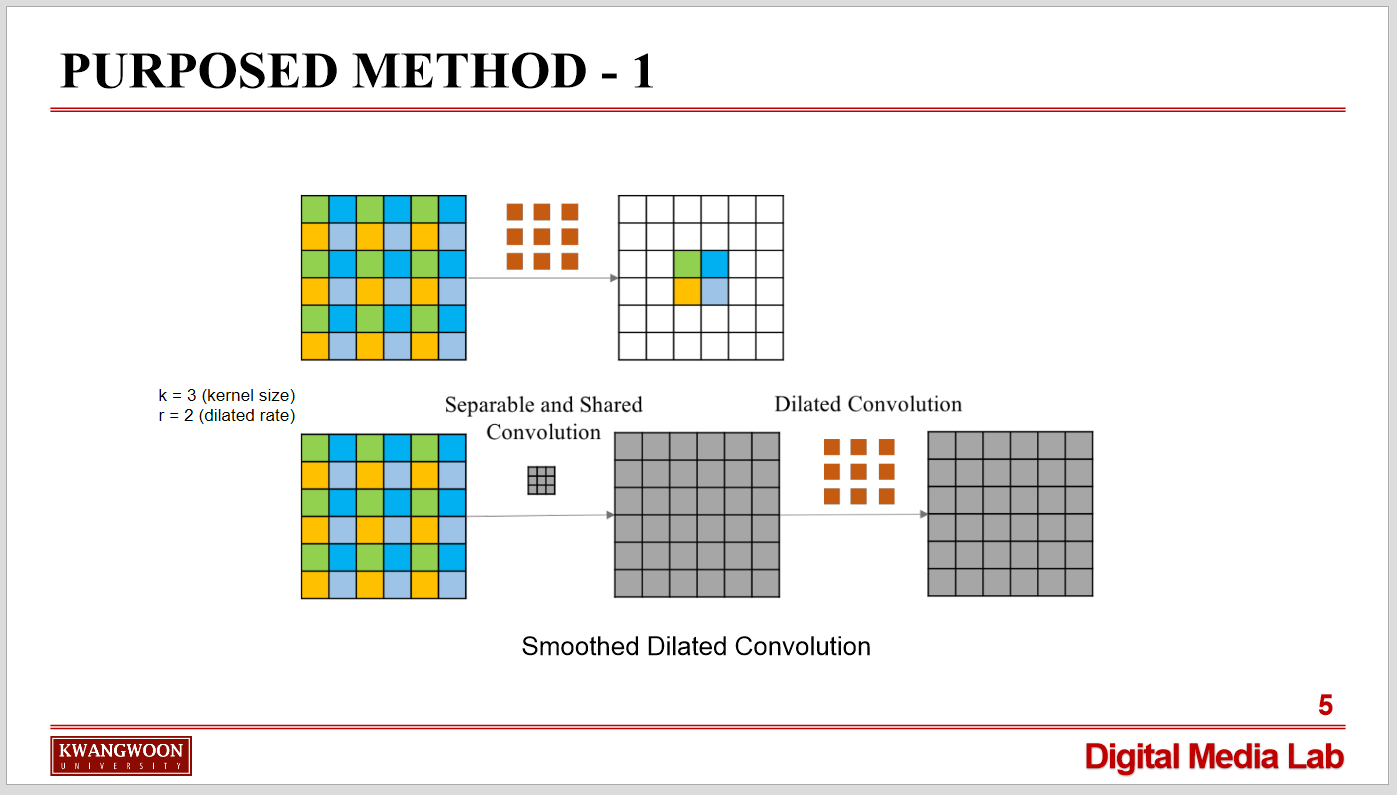
위 사진을 예로 들면, 커널 사이즈 k = 3, dilated rate r = 2 receptive field = 5곱하기 5 그리고 엑스트라 convloution layer의 filter 사이즈는 (2r - 1)인 3임을 알 수 있습니다.
Smoothed dilated convolution은 결과적으로 dilated convolution의 특성을 통해 해상도 감소를 완화함과 동시에 gridding artifact 현상 또한 해결한 모습입니다.
(논문상에서는 training에 사용한 데이터셋에 대한 정보를 단순히 벤치마크 데이터셋이라고만 표현했습니다.
그래서 이 논문이 인용한 논문인 Gated fusion network for single image dehazing이 사용한 dataset을 확인해 보았는데, 그 논문에선 1400장의 haze정보가 없는 클린한 이미지와 depth 맵, 즉 haze 정보를 합성한 데이터를 input 이미지로 사용했습니다.)
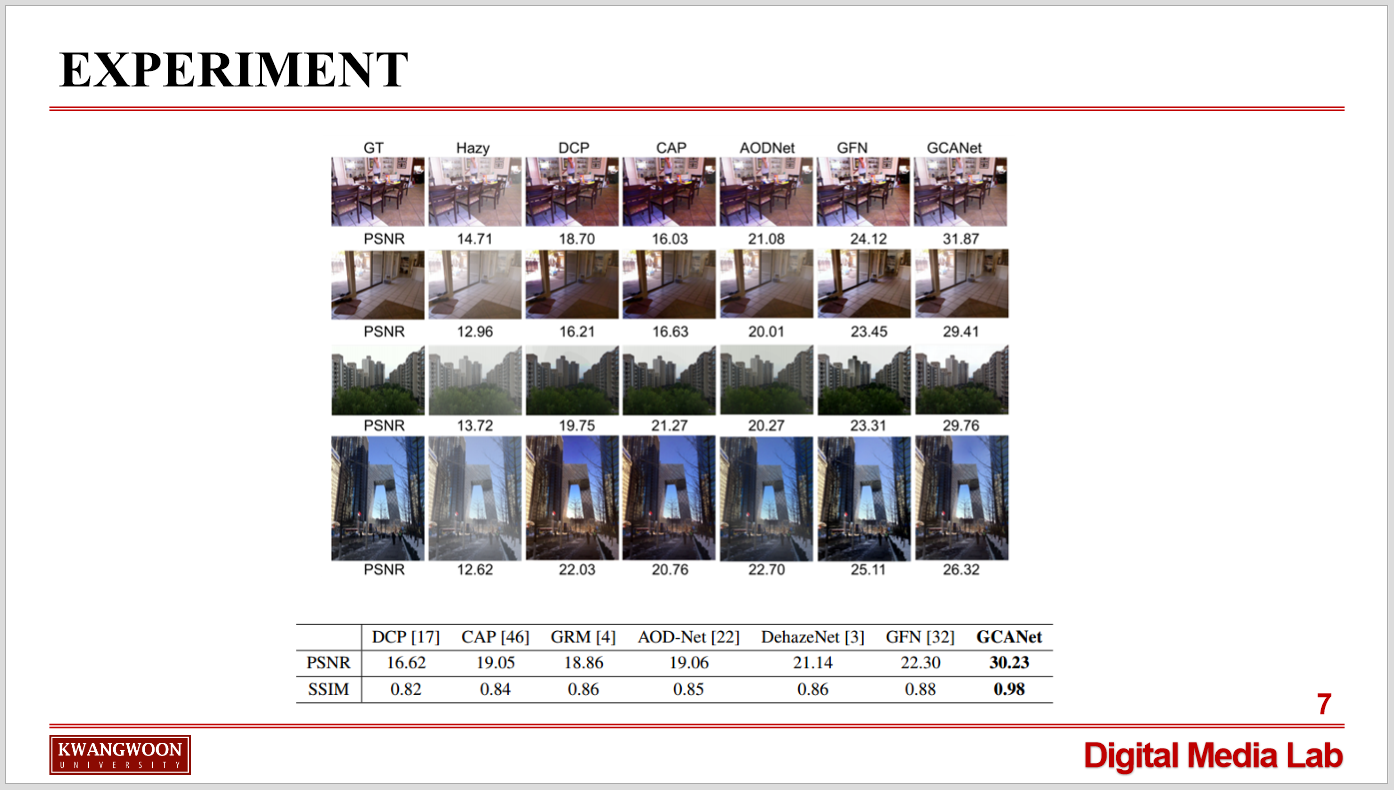
다음 이미지는 학습시킨 뉴럴 넷을 기존 존재하던 다른 모델들과 성능 비교를 한 표입니다.
성능 평가는 PSNR 및 SSIM 비교로 이루어졌습니다.
PSNR은 화질손실 정보를 나타내 주고, SSIM은 왜곡에 대한 원본과의 유사도를 나타냅니다.
본 모델이 상대적으로 PSNR이 높고, SSIM이 1에 가까운 모습 통해, 2018년 당시 가장 우수했던 논문임을 알 수 있습니다.
(PSNR은 최대 신호대 잡음비로서, 사진의 화질 손실 정보를 평가할 때 사용되며 PNSR이 높을수록 손실이 적음을 의미합니다.
또 SSIM은 변환에 의해 발생하는 왜곡에 대해 원본과의 유사도를 의미하며 1에 가까울수록 더 원본과 유사함을 의미합니다.
위 표를 보면 알 수 있듯이 본 논문은 타 모델들보다 가장 우수한 성능을 나타내었음을 알 수 있습니다.)


이 부분은 제가 본 논문의 코드를 통해 input 사진을 모델에 넣고 결과를 뽑아보았는데, 역시 haze 제거가 잘 된 걸 볼 수 있습니다.
 본 논문은 앞서 말한 smoothed dilated convolution 기법을 통해 haze 제거 부문에서 가장 우수한 성과를 내었습니다.
본 논문은 앞서 말한 smoothed dilated convolution 기법을 통해 haze 제거 부문에서 가장 우수한 성과를 내었습니다.
비를 제거하는 deraining 부문에서도 역시 PNSR 부문에서 모델들 중 가장 뛰어난 모습을 보였습니다.
감사합니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
class ShareSepConv(nn.Module):
def __init__(self, kernel_size):
super(ShareSepConv, self).__init__()
assert kernel_size % 2 == 1, 'kernel size should be odd'
self.padding = (kernel_size - 1)//2
weight_tensor = torch.zeros(1, 1, kernel_size, kernel_size)
weight_tensor[0, 0, (kernel_size-1)//2, (kernel_size-1)//2] = 1
self.weight = nn.Parameter(weight_tensor)
self.kernel_size = kernel_size
def forward(self, x):
inc = x.size(1)
expand_weight = self.weight.expand(inc, 1, self.kernel_size,
self.kernel_size).contiguous()
return F.conv2d(x, expand_weight,
None, 1, self.padding, 1, inc)
class SmoothDilatedResidualBlock(nn.Module):
def __init__(self, channel_num, dilation=1, group=1):
super(SmoothDilatedResidualBlock, self).__init__()
self.pre_conv1 = ShareSepConv(dilation*2-1)
self.conv1 = nn.Conv2d(channel_num, channel_num, 3, 1,
padding=dilation, dilation=dilation, groups=group, bias=False)
self.norm1 = nn.InstanceNorm2d(channel_num, affine=True)
self.pre_conv2 = ShareSepConv(dilation*2-1)
self.conv2 = nn.Conv2d(channel_num, channel_num, 3, 1,
padding=dilation, dilation=dilation, groups=group, bias=False)
self.norm2 = nn.InstanceNorm2d(channel_num, affine=True)
def forward(self, x):
y = F.relu(self.norm1(self.conv1(self.pre_conv1(x))))
y = self.norm2(self.conv2(self.pre_conv2(y)))
return F.relu(x+y)
class ResidualBlock(nn.Module):
def __init__(self, channel_num, dilation=1, group=1):
super(ResidualBlock, self).__init__()
self.conv1 = nn.Conv2d(channel_num, channel_num, 3, 1,
padding=dilation, dilation=dilation, groups=group, bias=False)
self.norm1 = nn.InstanceNorm2d(channel_num, affine=True)
self.conv2 = nn.Conv2d(channel_num, channel_num, 3, 1,
padding=dilation, dilation=dilation, groups=group, bias=False)
self.norm2 = nn.InstanceNorm2d(channel_num, affine=True)
def forward(self, x):
y = F.relu(self.norm1(self.conv1(x)))
y = self.norm2(self.conv2(y))
return F.relu(x+y)
class GCANet(nn.Module):
def __init__(self, in_c=4, out_c=3, only_residual=True):
super(GCANet, self).__init__()
self.conv1 = nn.Conv2d(in_c, 64, 3, 1, 1, bias=False)
self.norm1 = nn.InstanceNorm2d(64, affine=True)
self.conv2 = nn.Conv2d(64, 64, 3, 1, 1, bias=False)
self.norm2 = nn.InstanceNorm2d(64, affine=True)
self.conv3 = nn.Conv2d(64, 64, 3, 2, 1, bias=False)
self.norm3 = nn.InstanceNorm2d(64, affine=True)
self.res1 = SmoothDilatedResidualBlock(64, dilation=2)
self.res2 = SmoothDilatedResidualBlock(64, dilation=2)
self.res3 = SmoothDilatedResidualBlock(64, dilation=2)
self.res4 = SmoothDilatedResidualBlock(64, dilation=4)
self.res5 = SmoothDilatedResidualBlock(64, dilation=4)
self.res6 = SmoothDilatedResidualBlock(64, dilation=4)
self.res7 = ResidualBlock(64, dilation=1)
self.gate = nn.Conv2d(64 * 3, 3, 3, 1, 1, bias=True)
self.deconv3 = nn.ConvTranspose2d(64, 64, 4, 2, 1)
self.norm4 = nn.InstanceNorm2d(64, affine=True)
self.deconv2 = nn.Conv2d(64, 64, 3, 1, 1)
self.norm5 = nn.InstanceNorm2d(64, affine=True)
self.deconv1 = nn.Conv2d(64, out_c, 1)
self.only_residual = only_residual
def forward(self, x):
y = F.relu(self.norm1(self.conv1(x)))
y = F.relu(self.norm2(self.conv2(y)))
y1 = F.relu(self.norm3(self.conv3(y)))
y = self.res1(y1)
y = self.res2(y)
y = self.res3(y)
y2 = self.res4(y)
y = self.res5(y2)
y = self.res6(y)
y3 = self.res7(y)
gates = self.gate(torch.cat((y1, y2, y3), dim=1))
gated_y = y1 * gates[:, [0], :, :] + y2 * gates[:, [1], :, :] + y3 *
gates[:, [2], :, :]
y = F.relu(self.norm4(self.deconv3(gated_y)))
y = F.relu(self.norm5(self.deconv2(y)))
if self.only_residual:
y = self.deconv1(y)
else:
y = F.relu(self.deconv1(y))
return y
[출처] : https://github.com/cddlyf/GCANet/blob/master/GCANet.py
Subscribe via RSS