
Gated Context Aggregation Network for Image Dehazing and Deraining 논문 리뷰
by
본 논문은 여기에서 확인 할 수 있습니다.
Introduction

대기 중 안개나 먼지등으로 인해 이미지의 채도나 대비등이 손실되는 현상을 Hazing이라 합니다.
Hazed 된 이미지로부터 원본 이미지로 복원해 주는 논문은 꾸준히 나왔고 저는 이 중 2019년 당시 가장 복원율이 높았던 Gated Context Aggration Network for Image Dehazing And Deraing 논문을 리뷰했습니다.
Haze를 제거하는 이미지 Dehazing 작업은 딥러닝 의 발전 전후로 나뉩니다.
딥러닝 기술의 등장 전에는, 대부분의 기술은 아래 식을 보시면 알 수 있듯이 대기 투과율과, 대기 산란광인 자연광을 예측하는 방식으로 이루어졌습니다.
Purposed Methods
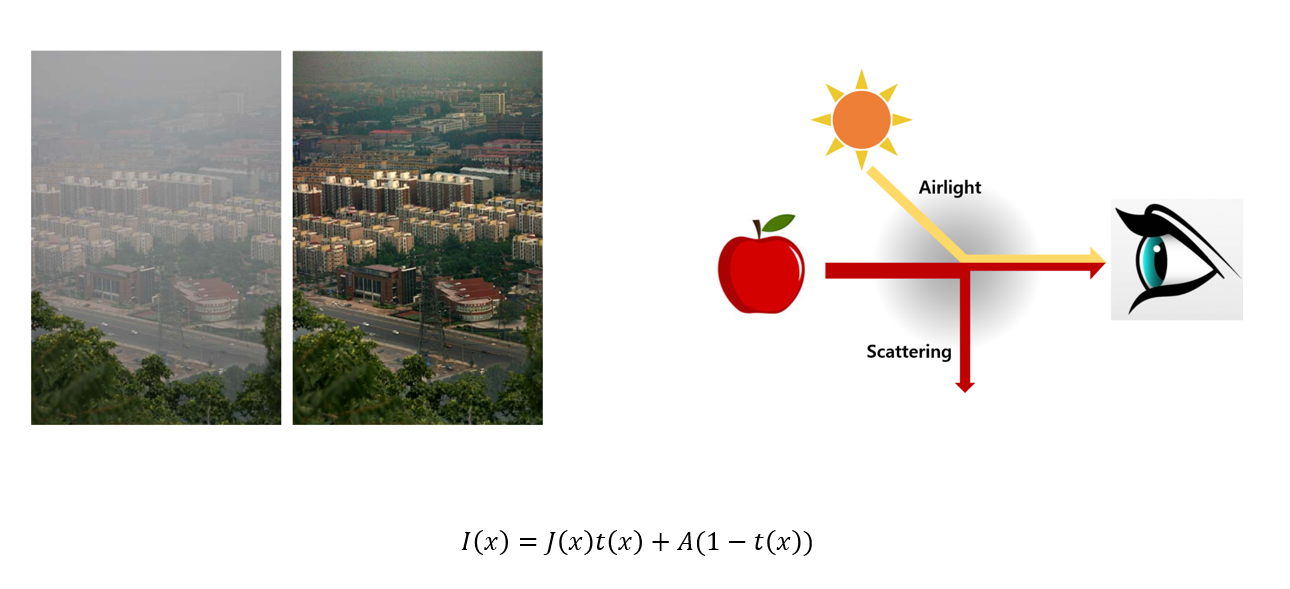
위 식에서
I(x)는 hazed 된 실제 카메라에 찍히는 이미지
j(x)는 haze에 의해 왜곡되기 전인 클린한 이미지
A 는 대기산란광
t(x)는 대기 투과율을 의미합니다.
이 식을 해석해 보면, 대상으로부터 반사된 신호 J(x)는 대기를 통과하면서 일부가 손실되어 J(x)곱하기 t(x)꼴이 되고, 이 신호에 주변 광원에 의해 형성된 A가 섞이게 되어 hazed 된 이미지인 I(x)가 관측자에게 도달됩니다.
클린한 이미지인 J(x)를 복원하기 위하여 t(x)와 A를 예측해야 했는데, 이는 매우 어려운 문제라서 복원 이미지인 J(x)는 실제 이미지와 같아지는게 쉽지 않았습니다.
딥러닝의 발전 이후, 더 이상 위의 식을 이용하여 자연광이나 대기투과율 등을 예측하지 않고, end to end 방식의 대용량의 training set을 이용하여 neural net 을 학습시켜 이미지 복원을 하는 기법이 연구되었습니다.
본 논문은 end to end 방식의 딥러닝 기법에 두 가지 기술인 Smoothed dilated convolution 기법과 Gated Fusion Sub-Network 을 추가하여 복원율을 높였습니다.
딥러닝 기반의 이미지 dehazing을 살펴보면, 딥러닝은 Neural Net과 saved 된 network weight를 활용하는 방식으로 이루어집니다.
매우 많은 수의 hazed된, 실제 카메라에 찍힌 이미지를 network의 input으로 주고, haze에 의해 왜곡되기 전인 클린한 이미지를 output으로 주어, haze만을 추출하는 Neural Net을 학습시킵니다. 그리고 그 과정에서 가중치인 weight를 저장합니다.
위의 과정을 토대로 많은 딥러닝 기반의 dehazing 기반의 논문들이 나왔고, 본 논문 역시 위 방식에 두 가지 기술을 더해 복원율을 높였습니다.
convolutional layer 앞에 extra convolutional layer을 추가한 smoothed dilated convolution 기술과, 서로 다른 레벨의 feature을 concatenate 한 gated fusion sub-network 기술입니다.
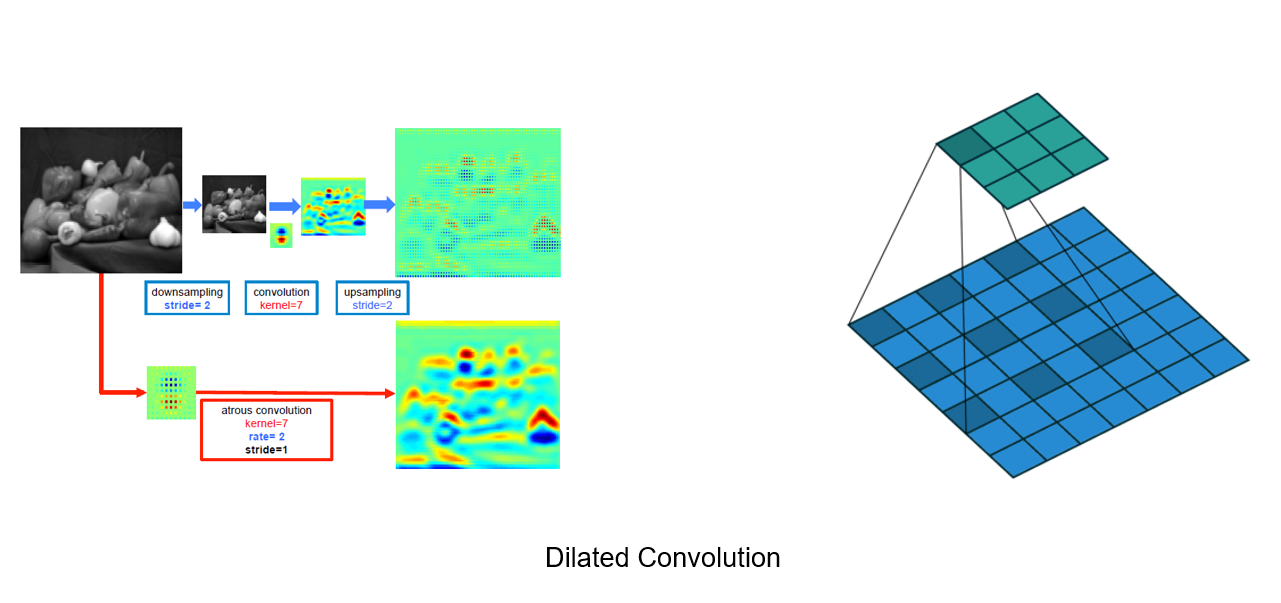
첫 번째 기술인 smoothed dilated convolution입니다.
Smoothed dilated convolution은, dilated convolution의 결점을 완화시킨 기술입니다.
dilated convolution부터 설명드리자면, dilated convolution은 다운샘플링과, 컨볼루션 그리고 업샘플링을 반복하는 뉴럴넷 모델에서 발생하는 해상도 손실을 줄여주는 기술입니다.
컨볼루션 레이어를 통해 이미지의 전체적인 특징을 잡아내기 위해서는, receptive field가 높을수록 좋은데, receptive field가 커지려면 filter size가 커져야 하고 이는 연산량 증가를 의미합니다.
따라서 receptive field 면적을 넓히기 위해 이미지를 다운샘플링 후, 컨볼루션을 하고 다시 업샘플링을 하는데 이 과정에서 해상도 저하가 일어납니다.
해상도 저하를 막기 위해, 인풋의 사이즈를 키워주고 그 늘어난 만큼의 사이 공간을 zero padding 한 후 위와 같이 컨볼루션 해주면, 다운샘플링, 업샘플링 과정이 없어도 되고 해상도 저하또한 없어지게 됩니다.
그런데 이 dilated convolution의 단점은, output 레이어에서 각 픽셀은 바로 옆 픽셀과 receptive field 정보가 전혀 다르고 이를 gridding artifact라 부릅니다.
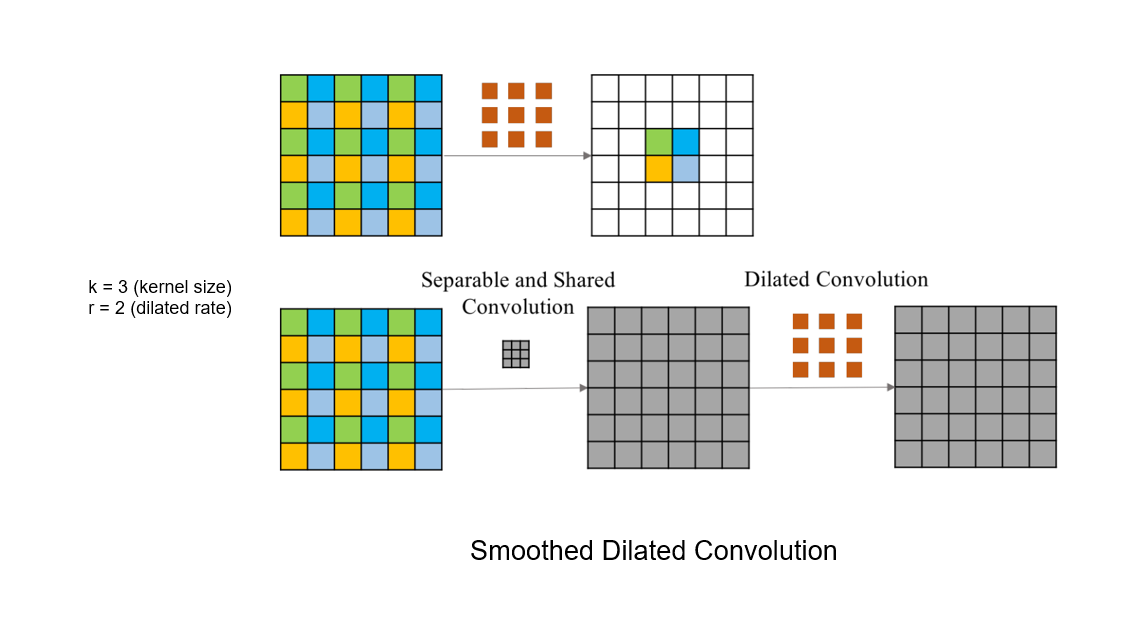
zero padding을 한 후 한 칸씩 간격을 두어 컨볼루션했기 떄문인데, 이 gridding artifact 현상을 막기 위해 smoothed dilated convolution는 컨볼루션 이전 층에 커널 사이즈 (2r – 1)의 extra convolutional layer를 추가해 줍니다. 여기서 r은 dilation rate를 의미합니다.
위 사진을 예로 들면, 커널 사이즈 k = 3, dilated rate r = 2 receptive field = 5곱하기 5 그리고 엑스트라 convloution layer의 filter 사이즈는 (2r - 1)인 3 임을 알 수 있습니다.
Smoothed dilated convolution은 결과적으로 dilated convolution의 장점인 해상도 감소를 완화하고, gridding artifact 현상 또한 해결한 모습입니다.
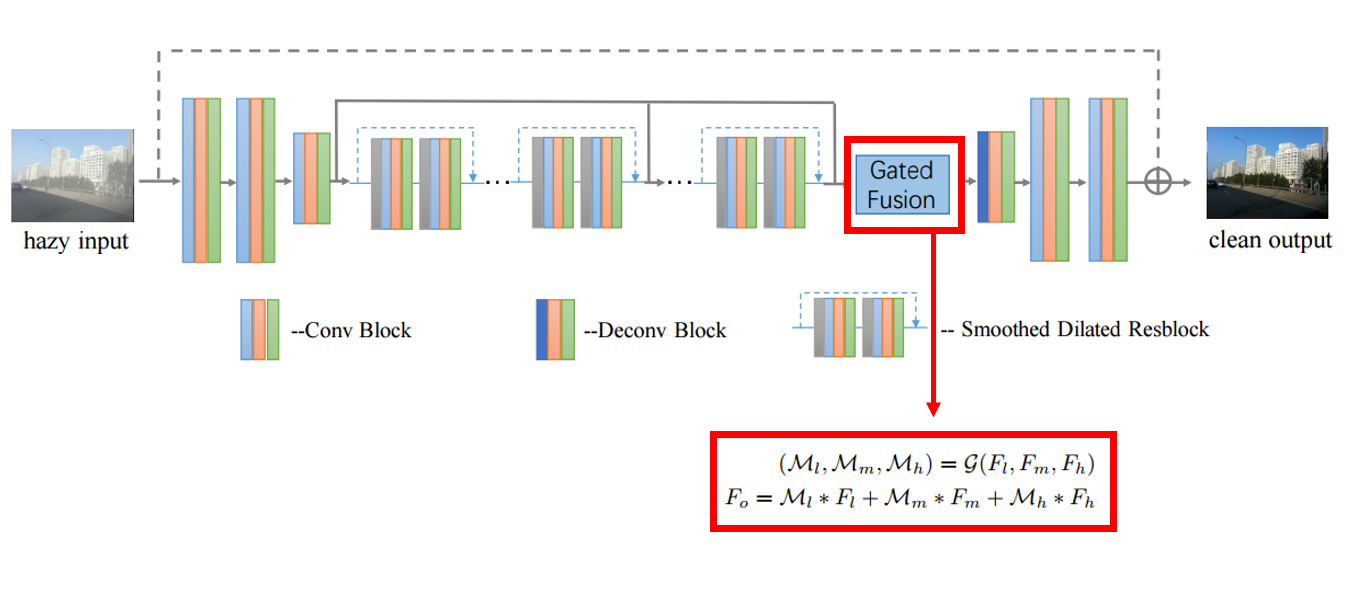
두 번쨰 기술은 Gated Fusion Sub-Network 입니다.
서로 다른 레벨의 피쳐맵을 융합하는 feature pyramids Network 방법은 low level 과 high level 작업 모두에 효과적입니다.
Gated Fusion Sub-Network는, 이 feature pyramids 방법을 이용하여 Residual 연산이 된 정도에 따라 구분한 세 가지 레벨의 feature map Fl,Fm,Fh 들을 gated fusion sub-network G 에 따라 concatenate 해줍니다.
여기서 l m h는 low middle high를 뜻하고 high에 가까울수록 residual 연산이 많이 이루어 졌음을 의미합니다.
End to end 방식으로 학습되어 regressed된 즉 haze를 제거하는데 가장 알맞게 학습된 weight인 Ml,Mm,Mh 가 각 레벨의 feature map (Fl,Fm,Fh)에 곱해지고 디코더의 입력으로 들어갈 한 층의 feature map인 Fo을 도출합니다.

Experiment
다음은 구현 부분입니다.
논문상에서는 training에 사용한 데이터셋에 대한 정보를 단순히 벤치마크 데이터셋이라고만 표현했습니다.
그래서 이 논문이 인용한 논문인 Gated fusion network for single image dehazing이 사용한 dataset을 확인해 보았는데, 그 논문에선 1400장의 haze정보가 없는 클린한 이미지와 depth 맵, 즉 haze 정보를 합성한 데이터를 input 이미지로 사용했습니다.
다음 이미지는 학습시킨 뉴럴 넷을 기존 존재하던 다른 모델들과 성능 비교를 한 표입니다. 성능 평가는 PSNR 및 SSIM 비교로 이루어졌습니다.
PSNR은 최대 신호대 잡음비로서, 사진의 화질 손실 정보를 평가할 때 사용되며 PNSR이 높을수록 손실이 적음을 의미합니다.
또, SSIM은 변환에 의해 발생하는 왜곡에 대해 원본과의 유사도를 의미하며 1에 가까울수록 더 원본과 유사함을 의미합니다.
위 표를 보면 알 수 있듯이 본 논문은 타 모델들보다 가장 우수한 성능을 나타내었음을 알 수 있습니다.
이 부분 부터는 제가 본 논문의 코드를 통해 input 사진을 모델에 넣고 결과를 뽑아보았는데, 역시 haze 제거가 잘 된 걸 볼 수 있습니다.
 (구현한 이미지 1)
(구현한 이미지 1)
 (구현한 이미지 2)
(구현한 이미지 2)
Conclusion
본 논문은 앞서 말한 smoothed dilated convolution 기법과 gated subnetwork 기법으로 haze 제거 부문에서 가장 우수한 성과를 내었습니다.
비를 제거하는 deraining 부문에서도 역시 PNSR 부문에서 모델들 중 가장 뛰어났습니다.
기존에 존재했던 모델들 보다 상대적으로 간단한 방식으로 19년 최고의 복원율을 보인 Gated Context Aggregation Network for Image Dehazing and Deraining 논문이었습니다.
감사합니다.
Subscribe via RSS